
目录
3.2.1、渲染目标Unordered Access 2D纹理变量
3.5、系统变量内嵌函数(Raytracing HLSL System Value Intrinsics)
4、Raytracing Shader编译和Shader中包含头文件的技巧
1、前言
经过了近一个多月的折腾之后,最终在我去蓬莱岛附近出差的过程中,终于搞定了DXR的第一个演示的例子。当然不排除可能是因为在蓬莱仙岛粘了仙气,才取得了突破性进展。整个过程还算正常,但是使用fallback库简直是让人痛不欲生,不过很幸运,这个该死的怪物还是被降服了。也怪自己囊中羞涩,有不起RTX20系显卡加持的电脑。
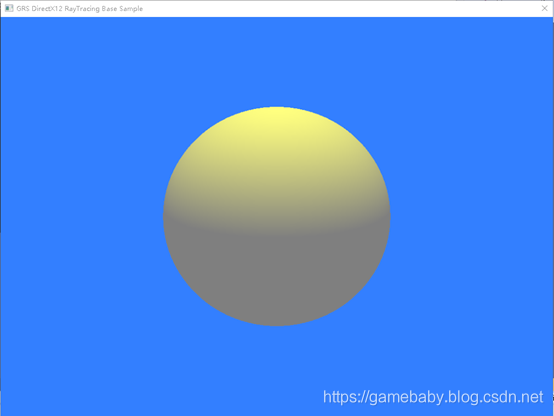
本次教程示例程序运行效果如下:

大家可以使用上下左右方向键来控制光源位置,看看初级光线追踪光线反射的效果。注意本质上讲,本示例中的光照模型依然使用的是光栅化渲染中的环境光+漫反射光模型,主要是为了先让大家理解整个框架,这里先不引入复杂的光照模型。
首先建议大家先阅读我的博客文章《光线追踪渲染(RayTracing Render)核心原理详解》之后,再来阅读学习本篇教程。篇幅的原因很多太理论化的东西我就不过多啰嗦了,本篇教程我们将集中精力在具体实在的编程方面,也就是大家常说的“干货”上。同时也建议大家也一定阅读了本系列教程中之前的系列文章,因为D3D12编程的基本框架依然适用于DXR编程,D3D12的基本编程技巧我也就不在啰嗦赘述了。
当然作为基础教程,我们的例子还是以简单为原则,当然依旧是几乎没有什么Class的C-Style的线性示例程序。同时比起复杂的光栅化渲染来说,光追渲染的过程理解起来也比较线性化。甚至可以这样认为,只要你线性代数基础好,光追渲染的过程中基本不会遇到太大的障碍。但是要警惕的是DXR和现在的fallback库可能反倒把事情搞复杂了。当然如果你有至少GTX10系以上的显卡的话,就不用理会什么fallback库了,复杂度会下降一大截,真正是人民币玩家的体验。
另外在这里告诉大家一个好消息:
参加中国DXR光线追踪开发者大赛,赢取NVIDIA RTX™显卡!
英伟达联合微软,Epic游戏,NExT Studios一起,为大家带来中国DXR光线追踪开发者大赛。游戏开发者与内容创作者可以利用Microsoft® DirectX® 12光线追踪的新特性,提交光追作品,赢取NVIDIA RTX™显卡大奖!
详情请见:https://developer.nvidia.com/DXR-spotlight
如您有兴趣报名,或希望了解更多详情,请邮件联系ChinaCM@nvidia.com获得支持。
将从比赛中选出优胜者,每位优胜者都将获得:
•NVIDIA RTX™显卡
•来自NVIDIA,微软,Epic Games,NExT Studios的开发者技术支持
•在NVIDIA,微软,Epic Games,NExT Studios的社交媒体渠道上展示成果。
如何参赛
●使用Microsoft® DirectX® 12和DXR创建实时光线追踪技术Demo。内容创作者/游戏开发者必须使用到实时光线追踪反射,实时阴影,实时GI的特性。
●将你的参赛作品递交到:https://developer.nvidia.com/dxr-contest-submission
o所有参赛作品的递交截止日期为:2019年10月31日晚11:59
o递交必须包含一个至少30秒的视频片断,以及技术demo下载地址
o游戏开发者需要提供一段简述,形容自己如何在技术demo中使用了微软DX12和DXR,以及实时光线追踪反射,GI,阴影与/或AO的特性。
OK,如果各位有兴趣参加,有什么技术问题都可以随时留言或微信QQ找我:41750362,本人将提供免费技术支持。当然不要问我参不参赛,水平实力有限就不去献丑了,请谅解!
言归正传,下面就让我们正式开始DirectX Raytracing(简写为DXR)之旅吧!
2、准备工作
目前因为我的硬件条件限制,所以在准备最简例子的过程中,不得不使用Fallback库来运行演示。其实本质上说,Fallback库就是用DirectComputer能力来模拟带硬件加速的DXR。因为我的显卡只是可怜的GTX965m,无法直接创建DXR设备及相关接口,所以只能使用Fallback库来模拟。
当然Fallback的使用对于初学者来说简直就是噩梦,幸运的是,我居然成功的驯服了这个大概是印度程序员写的怪兽。现在将过程分享给大家,方便我们在没有直接硬件DXR支持的情况下,能够成功的编写一些实时光追的示例程序,以便尽快的掌握DXR的编程技巧。
作为准备工作,第一步首先你要搞明白的就是将我们需要的库和其它相关资源统统复制到你的项目文件夹中,找到fallback库的目录,也就是DirectX-Graphics-Samples下的Libraries和Packages目录,如下图所示:


以及Tools目录:

然后把这三个目录都复制到你的项目中,如下图所示:



这里要注意的就是Libraries我们只复制了D3D12RaytracingFallback一个文件夹,其它的暂时不需要。
文件夹放好之后,需要在项目中加入Fallback的工程,如下图所示:

并且在主项目中首先引用fallbakclayer项目,如下图:

这样最终在编译中就会自动复制和链接fallback的lib。
这些基本工作做好之后,就需要对项目的各种属性和目录进行更改设置。首先需要修改项目引用的Windows SDK包,如下图所示:


接着需要对fallbacklayer项目的生成事件路径做适当修改:


经过这些路径修改设置后,生成文件的路径和位置就一致了,当然这些路径主要使用VS IDE的预定义宏来设置,这样整个项目复制粘贴到别的地方就依然能够正常使用。
最后一个需要注意的问题,就是因为fallbacklayer项目使用了PIX支持,所以我们还需要把刚才复制的packages进行一下导入。这个导入使用NuGet,操作如下图所示:

就是在整个解决方案目录节点的右键菜单中点击图中箭头所示的NuGet包管理菜单,然后在弹出的界面中做如下设置:

在这个NuGet包管理对话框中,点击加号按钮,将我们开始复制到项目目录里的packages中的WinPixEventRuntime.1.0.180612001.nupkg包文件加入项目引用包中,这样在解决方案的根目录下就会生成一个Packages的包文件夹,里面就是我们导入的WinPix支持包了,这样编译fallbacklayer项目就没有什么问题了。
至于NuGet的进一步说明和使用方法介绍我就不多啰嗦了,大家可以去百度一下就明白了了。
以上这些准备工作,我主要是靠图和简明扼要的说明介绍一下,大家遇到什么问题可以留言垂询。因为对于有条件的网友来说,fallback基本上可以不用理会了,所以我们这里就简单的介绍一下,以便有跟我一样的网友使用老设备想尝鲜,可以方便的引用fallback库了。
在最新的DXR示例中,实质上已经删除了fallback的引用,直接使用纯DXR演示了,所以对于最新的DXR Samples,如果不是GTX10xx系或RTX20xx系以上的显卡,就没法直接运行了,这个大家要注意。
对于找不到这些包的网友不用着急,本章教程所有的示例我已经放在了GitHub上免费开放了(GRSDXRSamples),大家可以随时Clone,下载自己调试运行学习。
3、Raytracing Shader
在我的博客文章《光线追踪渲染(RayTracing Render)核心原理详解》中我已经简单介绍了Raytracing Shader的基本框架。
本章教程中,我们直接使用微软官方例子D3D12RaytracingSimpleLighting项目中的Raytracing.hlsl。当然为了教程统一风格需要,其中做了一些变量名替换。
这里我详细介绍下该Shader中的变量和函数,也算是让大家初步掌握Raytracing Shader的基本编写方法。完整代码请大家到GitHub下载后自行查看,我就不贴完整的源码了。
因为现在使用实时光追渲染之后,本质上整个渲染管线都紧密围绕Raytracing Shader展开了(其实光栅化也是,只是光栅化固定的阶段较多,代码中要做的工作也比较多,所以光栅化部分就主要围绕C /C++代码部分进行了详细讲解),所以DXR编程的框架实际也是围绕让管线运行起来而展开的。
基于此,在这里就先来学习下Raytracing Shader的基本框架和光追计算的核心思想,这种安排与之前的教程有所区别。当然前提就是至少你已经阅读了我之前的系列教程,对D3D12接口编程已经有了比较全面整体的认知,尤其要掌握基本的设备创建、命令队列、命令列表、根签名、管线状态对象、网格加载、纹理加载、采样器、资源屏障、同步围栏等对象的概念和基本编程方法,最好进一步对D3D12内存管理有较深刻的认识。不明白的话,建议你先暂停,折回头去看下之前的教程,再来这里继续学习。
注意:前方高能警告!
3.1、Raytracing Shader整体框架介绍
首先,从整体上看,光追渲染的Shader程序框架与DirectComputer Shader比较接近。
其实从本质上说,光追渲染计算更加的偏“自由计算”化,原理上是不断的计算生成光线(射线),然后检测光线与物体(AABBs)及其表面三角形碰撞的情况,然后根据碰撞点的三角形重心坐标,调用对应的各种“光照”算法(BRDFs),最终生成像素点(也就是光线起点)颜色的过程(一般是取n个计算颜色值结果的算数平均值)。
在实时光追渲染中已经没有光栅化渲染过程中的那些比较固定的计算阶段了。比如非常关键的光栅化(Rasterizer)过程,在传统的光栅化渲染框架或管线中就纯粹固化到硬件上了(当然DX支持你自己使用软件实现一个光栅化模块,对于一些更高级更灵活的光栅化渲染来说这种方式的诱人之处就是“可编程”)。由于这些相对固化的阶段,将整个光栅化渲染管线分成了若干个阶段(Stages),也就形成了光栅化渲染管线的基本框架。当然在现代的光栅化渲染管线中很多阶段已经可以编程了,所以光栅化渲染管线也被称为“可编程管线”(注意不是“全编程管线”,目前无论光栅化渲染管线还是实时光追渲染管线都没有做到“全编程管线”。非实时光追渲染管线则是另一回事了。)。
甚至在更早期,3D显卡(那时候甚至还没有GPU的概念)上将整个光栅化渲染过程全部固化在了芯片中,相对形成了比较专用的加速卡的形式。这样做的目的其实无外乎几个目的,首先就是为了性能,那时甚至每秒能渲染多少三角形成了衡量3D加速卡的关键性能指标之一。其次就是整个光栅化的渲染思路就是不断的剔除多余的三角形,最终目标就是只渲染能“看”到的少量三角形,并且使用简化的光照模型,通过修改一些参数(比如:高光系数、漫反射光颜色,环境光颜色值等)的方式来最终决定屏幕像素的颜色,从而形成所谓的“3D渲染的画面”。
后来随着芯片运算能力的提高,逐步出现了可以编程的一些管线阶段,比如著名的Vertex Shader 和Pixel Shader,在其中3D程序员可以通过纯粹编程的方式来局部控制整个光栅化渲染的过程。但是整体来看那时3D渲染管线和过程是相对固定的。甚至彼时这些可编程的渲染阶段:VS、HS、DS、GS、PS等都有一些根本上的限制。比如VS中你就只能计算当前传入的那个顶点,只有GS有生成新顶点和新几何体的能力,而更高级的阴影实现甚至需要所谓的多趟渲染+蜡板来实现。复杂度成几何级数级增加。
而在GPU计算能力爆炸式增长的今天,实时光追渲染也成为了可能。因为在实时光追渲染的过程中,只有极少数的相对固定的计算过程,也就是说很少能通过调整几个参数来控制或调节整个渲染过程了。更直接的说,光追渲染过程本质是一个必须进行“通用计算”的过程,而不能像传统的光栅化渲染那样简单的实现“参数化”设计,它更偏向于需要“自由编程”能力了,比如为了极致的渲染效果传统的固化的BRDFs效果,就可能需要实时的蒙特卡洛积分计算来模拟了。
因此最终Raytracing Shader框架与用于通用计算的DirectComputer Shader框架就很类似,这也很容易理解了。二者都是需要“通用计算”的“自由编程”的能力。
这样与DirectComputer Sheder相类似,Raytracing Shader一级结构我们可以理解为像下图所示:

Raytracing Shader的较详细的基本架构如下:
|
全局变量定义 |
包含文件(#include) |
|
渲染目标(RWTexture2D) |
|
|
网格数据(Vertex、Index) |
|
|
常量缓冲(ConstantBuffer) |
|
|
加速结构(RaytracingAccelerationStructure) |
|
|
基本碰撞(命中检测)函数 |
其它辅助工具函数 |
|
光线发射函数([shader("raygeneration")]) |
|
|
最近碰撞函数([shader("closesthit")]) |
|
|
未碰撞函数([shader("miss")]) |
当然作为最一般的光追渲染来说,这个框架基本已经满足需要了。其它更复杂的元素,后续的教程中遇到时我们再逐个介绍。目前的应用来说这已经足够了。
3.2、全局变量
3.2.1、渲染目标Unordered Access 2D纹理变量
在Raytracing Shader中,我们首先要定义的变量就是:
RWTexture2D<float4> g_RenderTarget : register(u0);这个变量代表整个实时光追渲染的输出画面,与传统的光栅化渲染不同,这里实质上是一个纯粹的渲染到纹理的方式。只是这个纹理我们使用的是一个可“Unordered Accesses(无序访问 或 随机访问)” 读写的2D纹理。
如何理解这个设计要求呢?那么首先渲染到2D纹理很容易理解,因为从本质来讲,最一般的光栅化渲染到交换链的后缓冲区,其实也就是渲染到一个2D纹理。而比较难理解的就是为什么非得是Unordered Access的纹理呢?这其实也是两种渲染方式巨大的差异导致的结果。传统的光栅化渲染在光栅化阶段,以及后续的Pixel Shader像素着色阶段,其实每个像素的颜色基本都是在同一个Shader计算过程(或理解为几乎相同的同一个Shader函数调用路径)中决定的,因此可以简单形象的理解为一个线程(GPU线程)操作一个内存单元格,没有什么特殊的地方。在最终写入像素颜色值时基本也是“同时”写入每个像素的。这种情景,你可以形象的想象一排排列非常整齐的射手,以相同的姿势,同时举枪射击各自面前的靶子,在发令官一声令下后,大家几乎同时开枪,然后子弹几乎同时射中靶子的情形。
而在实时光追渲染中,那么决定每个像素的最终颜色的Shader可能就不是一个了,或者说Shader函数及调用路径基本都不一样了,主要是因为我们现在执行的是光线的动态追踪,看过我的《光线追踪渲染(RayTracing Render)核心原理详解》之后,我们知道光追渲染其实就是每个像素都朝一个视锥体内的特定方向“发射”一条光线(射线),在光线不断碰撞-反射-折射的过程中到达光源后再调用不同的Shader计算决定最终的颜色值,因此一个像素最终的颜色可能会跨越不同的函数及计算路径得到,所以可能每个像素最终被着色的时间点也会出入很大,导致最终写入每个像素的颜色值的时机基本都是“随机的”,因为每条光线的路径都可能是不同的。同时按照现代GPU对于显存的近乎严苛的管理要求,我们必须明确的告诉GPU渲染目标2D纹理是需要“随机访问”的,这就是Unordered Access形式2D纹理作为实时光追渲染目标的全部意义。这种情形可以与之前的例子对应想象为在一个真实的战场上,士兵都分散在近乎随机分布的散兵坑里射击,开枪的时机,子弹的路径,射击目标的类型、射击的时机、射中没射中等等都几乎是随机的一样。
当然这也是典型的DirectComputer计算结果缓冲需要的类型形式。
总之,本质上g_RenderTarget这个变量代表一块纹理(也就是一块显存,放在“默认堆”上),但与普通的只读纹理不同,它是需要可读写的,同时要求是可以随机访问的,这里的随机访问是针对GPU线程而言的。其基本访问单位是float4,即渲染结果图片上的每个像素点的最终颜色值。它的实质大小就在C++代码中设定,逻辑大小(像素数)一般是窗口的大小iWidth * iHeight,字节大小就是iWidth *iHeight*4*sizeof(float)。因为它放在默认堆也就是显存中,所以GPU访问速度很高,因为需要随机读写,比GPU访问一般的只读纹理速度要慢一些,但快过访问共享内存中的上传堆中缓冲的速度。
3.2.2、三角形网格变量
接下来的两个变量:
ByteAddressBuffer g_Indices : register(t1, space0);
StructuredBuffer<ST_GRS_VERTEX> g_Vertices : register(t2, space0);就是我们需要渲染的物体的网格数据,一般就是三角形网格数据,即三角形顶点数组及其对应的索引数组。
在传统的光栅化渲染中,因为渲染管线设计的相对固化,三角形网格数据传入渲染管线都是通过专门的函数: IASetVertexBuffers、IASetIndexBuffer等来设置并传入的,而且在代码层面我们还要设置网格数据格式,通过管线对象结构体成员D3D12_GRAPHICS_PIPELINE_STATE_DESC::InputLayout 以及函数IASetPrimitiveTopology等来设定,同时这也是底层驱动和硬件直接支持的,性能上就有一些优势。当然换个角度来看这其实也是一种束缚和限制,也体现出传统光栅化渲染框架的要求下,其实从硬件开始就对数据类型做了非常细致的划分,而划分的目的无非就是为了限制不必要的数据计算扩展,比如早期你不能使用纹理来上传顶点数据,你更不能说在顶点数据中传入纹理数据,或者说作用于纹理上的指令是不能操作顶点数据的反之亦然。这些其实都是为了简化指令设计,从而最终提高性能的设计。因为归根结底,GPU是一个大的SIMD架构的处理芯片,高并行,超大数据量吞吐才是其终极目的。
现在随着GPU指令集加强,数据类型处理限制的逐步解除,以及处理能力的不断提升,尤其是GPU“通用计算”能力的不断提升,使得实时光追也成为可能,我们就可以在Raytracing Shader中以缓冲区的方式直接简单的传入网格顶点的数据,甚至于网格顶点数据的整体数据结构都由代码和Shader自行负责,我们不需要过多的额外的编程限制了。比如我们不需要反复的通过InputLayout结构体数组与GPU沟通网格顶点的数据结构了。
总之,ByteAddressBuffer类型是个Shader的内置的数据类型,其含义就是BYTE*,甚至我们可以将其理解为VOID*,也就是说这种缓冲里的数据我们可以按照以字节为单位大小随意访问,这样我们传入的网格索引数组,就可以按我们需要来访问了。后续我们在介绍函数时还会详细介绍这个缓冲区。其大小则是由代码中指定的。这也提现了Raytracing Shader在编码方面的的巨大灵活性。当然我们还是需要指定是从哪个寄存器组传入的,后面的register(t1, space0)语义说明我们依然是从纹理的寄存器通道1(实质是第二个寄存器,因为有0序号寄存器是第一个,与C/C++中数组下标类似,从0开始)上传顶点索引数据,此时我们也发现现在所谓“纹理”数据类型其实质可代表的类型已经大大的丰富了,当然对应的操作指令也丰富了,使得我们现在都可以直接传入BYTE*这种“极端自由”的数据。
紧接着顶点索引的是StructuredBuffer<ST_GRS_VERTEX>类型定义的顶点数据数组g_Vertices,那么这个类型定义有些像C++中的模板实例化的语法,即我们可以将StructuredBuffer认为是一个纯数组容器模板类,而在Shader中它被我们用自定义的顶点数据类型ST_GRS_VERTEX结构体实例化了,这样它其实要表达的意思就是ST_GRS_VERTEX g_Vertices[],也就是网格顶点数据的数组。而register(t2, space0)语义文法则跟刚才一样说明顶点数组是从“第三个纹理寄存器”传入的。
3.2.3、常量缓冲
接下来的两个常量结构体的定义:
ConstantBuffer<ST_SCENE_CONSANTBUFFER> g_stSceneCB : register(b0);
ConstantBuffer<ST_MODULE_CONSANTBUFFER> g_stModuleCB : register(b1);与我们在一般的VS或PS中定义常量缓冲的方式有些不同,一般在我们之前的例子中都像下面这样来定义常量缓冲区:
cbuffer MVPBuffer : register(b0)
{
float4x4 m_MVP;
};其实两种定义方法的含义是一样的,只是在Raytracing Shader中我们使用的是类似DirectComputer中的常量缓冲的定义方法。从文法上我们可以将ConstantBuffer<ST_SCENE_CONSANTBUFFER>理解为一个模板实例化类型定义。只是这里ConstantBuffer是个单例实例化,即它只实例化一个结构体为常量缓冲区,并不像其他的Buffer类型那样实例化成数组,这里可以直接的理解为类似C/C++代码中的定义:ST_SCENE_CONSANTBUFFER g_stSceneCB;。当然常量缓冲区使用的寄存器就是b族寄存器了。
在这里常量缓冲区稍微做了一些区分,即第一个常量缓冲区是全局可见的,即所有的光追阶段Shader函数都可以访问,我们后续将在代码中在全局根签名中声明并传入。而第二个则是局部可见的,即在我们目前的Shader里只是在检测到碰撞之后的Shader函数中才能够访问。
3.2.4、加速结构体变量
在接下来的全局变量定义:
RaytracingAccelerationStructure g_asScene : register(t0, space0);这个就是Raytracing Shader中特有的一个结构化缓冲区了,即我们在《光线追踪渲染(RayTracing Render)核心原理详解》一文中给大家介绍过得加速体结构的缓冲区。这个变量的定义其实在我们的Raytracing Shader中可以看做是一个“哑元”,即我们只是声明它,几乎不直接在我们的Shader中“显式”的操作它,而最终操作它的就是驱动和GPU(或 fallback库)。关于它的进一步的知识我们后续在创建和上传该缓冲时,在详细介绍。在Raytracing Shader中这几乎是唯一一个“黑盒式”的缓冲区,即我们不知道其具体结构,更无法操作其内部元素,当然我们也无需知道这些。
3.3、基本光线追踪渲染过程框架
与传统的光栅化渲染管线不同,实时光追渲染过程(或者称之为光追渲染管线)在过程上要简单的多。整体上如下图所示:

1、图中每个深灰色背景块都代表一个完整独立的Shader函数过程(包括子函数),绿色部分表示有硬件加速的过程。
2、图中:

这一部分实际是光追渲染过程中相对固定的部分,可以理解为光栅化渲染中的完全硬件固化的光栅化过程。而其中的Any Hit以及Intersection两个过程是可编程的部分,如果不指定专门的Shader函数的话,它们就执行默认的碰撞检测过程,可以理解为是先检测是否与物体的AABBs相交,接着检测与物体上的某个三角形相交,可以理解为就是一个“Pick(拾取)”的过程。
3、RayGeneration函数中实际要调用的最重要的Raytracing Shader内置方法就是:TraceRay(实际发射光线的函数,后面详细介绍),所以为了跟其他的自定义名称的方法区别这个方法的名字在图中使用了斜体标识。
4、图中实线箭头是一次光线的路径,也就是主要光追渲染过程,而虚线箭头表示的则是二次以上的光线(当然也要走一遍实线的过程),也就是说在Miss或Closest Hit的过程中还可以继续重复调用TraceRay()方法再次发射出光线,这通常用于高级渲染效果的情况,如:反射、阴影、折射、透射等。
通常在这两个方法(Miss或Closest Hit)中发射的光线(射线)就被称为“二次光线”或“高次光线”。一般情况下,在实时光追渲染中,使用到二次光线时已经可以有较高渲染质量了,为性能考虑不建议再生成更高次的光线(这是与一般光追渲染的区别,一般渲染光追中都会有大量的高次光线)。当然最终这又是一个需要在渲染质量和性能之间折中考虑的编程问题。
下面就让我们来认识每一个具体的Shader函数都是干嘛的。
3.4、光线发射函数(Ray Generation)
在本章教程的Shader中,我们定义的光线发射函数如下:
3.4.1、MyRaygenShader函数
[shader("raygeneration")]
void MyRaygenShader()
{
float3 rayDir;
float3 origin;
// Generate a ray for a camera pixel corresponding to an index from the dispatched 2D grid.
GenerateCameraRay(DispatchRaysIndex().xy, origin, rayDir);
// Trace the ray.
// Set the ray's extents.
RayDesc ray;
ray.Origin = origin;
ray.Direction = rayDir;
// Set TMin to a non-zero small value to avoid aliasing issues due to floating - point errors.
// TMin should be kept small to prevent missing geometry at close contact areas.
ray.TMin = 0.001;
ray.TMax = 10000.0;
RayPayload payload = { float4(0, 0, 0, 0) };
TraceRay(g_asScene, RAY_FLAG_CULL_BACK_FACING_TRIANGLES, ~0, 0, 1, 0, ray, payload);
// Write the raytraced color to the output texture.
g_RenderTarget[DispatchRaysIndex().xy] = payload.color;
}
1、函数“MyRaygenShader”,是必须自定义的“光线产生函数”,其名称可以是任意合法的标识符名称,当然你需要在代码中也知道他们的名字。这个函数对应实时光追渲染管线图中开始的Ray Generation函数。
2、这个函数顶部的[shader("raygeneration")]是个函数语义文法,用于标识其后的函数定义就是光追渲染的Ray Generation方法。当然这也是为了告诉Raytracing Shader编译器、DXR接口以及显卡驱动和对应硬件的一个标识,即被该语义修饰的函数就是“光线发生函数”。每个GPU线程(或者理解为单个流处理器)在执行实时光追渲染的过程时,就知道需要从这个方法开始执行(类似C/C++函数中的main函数)。
3、光线发生函数(Ray Generation)的一个核心工作就是计算光线方向,从而生成光线(射线)的向量方程,而后续的计算就利用这个射线向量方程来计算碰撞、碰撞点,从而检索一个Shader Table列表(实质是Shader函数列表)中对应的Shder(函数)进一步计算颜色值。
4、该函数首先取得像素点坐标,其次计算出对应像素点在摄像机坐标中的位置向量,然后在根据摄像机位置向量,计算出光线的方向。
根据光追基本原理,光线方向向量(Rey Dir)=像素点位置向量(Pixel Pos)- 摄像机位置向量(Camera/Eye Pos)。根据向量减法的规则,最终光线方向就从摄像机位置指向屏幕像素方向。原理示意图如下:

而光线(射线 Ray)的起点就是屏幕像素位置向量(大家一定要注意我这里就没有再区分表示点的坐标和向量之间的区别了,具有请参考光追原理一文)。这个计算过程更形象的如下图所示:

5、有了光线方向,那么接下来函数中拼装了一个光线方程(射线方程),其实就是我们说过的方程:Ray = Origin +t*Dir(TMin < t < TMax)。当然在代码中它是通过填充一个RayDesc结构体构建的。然后再声明一个PayLoad(光追负载,主要就是最终像素的颜色)的自定义结构体,最终调用TraceRay函数发射光线,(该函数是个“同步函数”,后面会详细说明),调用返回后,负载中就是像素点的颜色值,我们赋给对应像素的纹理单元即可。
3.4.2、GenerateCameraRay函数
在MyRaygenShader函数中,通过调用子函数GenerateCameraRay计算得到光线(射线的方程)的起点和方向,该函数定义如下:
inline void GenerateCameraRay(uint2 index, out float3 origin, out float3 direction)
{
float2 xy = index + 0.5f; // center in the middle of the pixel.
float2 screenPos = xy / DispatchRaysDimensions().xy * 2.0 - 1.0;
// Invert Y for DirectX-style coordinates.
screenPos.y = -screenPos.y;
// Unproject the pixel coordinate into a ray.
float4 world = mul(float4(screenPos, 0, 1), g_stSceneCB.m_mxP2W);
world.xyz /= world.w;
origin = g_stSceneCB.m_vCameraPos.xyz;
direction = normalize(world.xyz - origin);
}1、首先GenerateCameraRay函数的输入参数index其实就是屏幕像素点的坐标,当然坐标值是以屏幕坐标系为参考系的,即原点在屏幕(窗口左上角),X轴正方向朝右,Y轴正向朝下方。对应最大值分别是屏幕(窗口)的Width和Height。
2、index参数的值是通过调用名为DispatchRaysIndex()的 “系统变量内嵌函数”得到的(系统变量内嵌函数稍后会详细介绍)。该函数返回当前GPU计算线程的单元(可以理解为GPU上几千个流处理器中的一个)被分配计算的某个屏幕像素坐标x,y值。
3、紧接着通过将index与另一个“系统变量内嵌函数” DispatchRaysDimensions()的返回值做除法,其实也就是计算“归一化(normalization)”坐标值,将原来的像素坐标变换为(0-1.0f)之间的坐标,然后再*2.0f-1.0f,就进一步将像素坐标变换到了以屏幕中心为原点的归一化坐标系中,而值就变化到(-1.0f-1.0f)之间。这个计算过程对应原理图如下:

图中大写X,Y表示像素单位的坐标大小,小写的x,y表示标准化之后的坐标。同时我们注意到屏幕像素坐标系的Y轴正方向向下,而标准化坐标系为了与D3D的坐标系保持一致其Y轴是朝上的,所以在坐标换算的时候我们取归一化之后的负值即可。代码中也是将这些计算拆开步骤来写,大家应该立刻就能明白函数中的计算。
其实我们在《DirectX12(D3D12)基础教程(七)——渲染到纹理、正交投影、UI渲染基础》中介绍的基于窗口坐标系的正交变换差不多就是这里变换的逆变换。
4、函数中的第四行代码float4 world = mul(float4(screenPos, 0, 1), g_stSceneCB.m_mxP2W);就是将计算得到的屏幕像素标准化坐标扩展的4维齐次坐标空间,其Z坐标为0,即我们假设的屏幕平面就在z=0的平面上。当然齐次w坐标是1.0f,表示我们将这个扩展的坐标理解为是一个表示点的向量,也就是屏幕像素点在摄像机空间中的坐标。接着我们用屏幕像素点的标准化坐标乘以摄像机投影矩阵(Projection Matrix)的逆矩阵,意思就是说我们将这个点从摄像机坐标系变换到了世界坐标系中。接着world.xyz /= world.w;就保证了坐标单位大小的一致性(仿射变换)。
5、最后我们取摄像机的位置向量,作为起点坐标(origin = g_stSceneCB.m_vCameraPos.xyz;),然后利用变换到世界坐标系中的屏幕像素点位置坐标减去起点坐标就得到了光线的方向向量(direction = normalize(world.xyz – origin);),注意这里丢弃了两个向量坐标的w坐标,根据我们之前文章中介绍过的,4维齐次坐标系中,w=0的4维向量表示3D中的纯方向量(无位置),而当w=1时就表示3D中的点(有位置)。所以这里也可以写成如下形式:
world.xyzw /= world.w;
float4 origin =float4( g_stSceneCB.m_vCameraPos.xyz,1.0f);
float4 direction = normalize(world - origin);//4D向量表示法6、最后我们要注意的就是起点坐标origin我们直接用了摄像机的位置坐标,并没有做到世界空间变换的操作(也即没有乘以变换矩阵),这是因为实质上我们的摄像机位置坐标已经是世界坐标系中的坐标值了,不需要变换了。而屏幕位置坐标是相对于摄像机坐标系空间设置的坐标值,它必定在摄像机的坐标系中,并且我们总假设屏幕就是在摄像机坐标系的原点位置处,并且其方程永远是z=0。除非你想“斜视”,那么可以设置一个不在z平面上的屏幕平面方程试试,估计你会有惊喜。
3.4.3、TraceRay函数
最后有了光线(射线)的方程之后,我们就可以开始正式的光追计算过程了,而核心就是调用TraceRay函数,其原型如下:
Template<payload_t>
void TraceRay(RaytracingAccelerationStructure AccelerationStructure,
uint RayFlags,
uint InstanceInclusionMask,
uint RayContributionToHitGroupIndex,
uint MultiplierForGeometryContributionToHitGroupIndex,
uint MissShaderIndex,
RayDesc Ray,
inout payload_t Payload);1、这个函数的声明使用了模板化声明,主要的模板参数就是payload_t,即光追渲染的负载,通常我们设定为最终屏幕像素点颜色变量的引用。这个参数会被原封不动的以纯引用的方式传递给所有后续的光追渲染函数,后续的这些函数就可以将计算的颜色值写入该模板变量,最终TraceRay返回后,PayLoad中就是计算得到的像素点颜色值;
2、第一个参数AccelerationStructure就是刚才介绍的加速体结构变量;
3、第二个参数RayFlags是指定光追碰撞检测(命中检测)时最终对三角形执行的操作类型,这个类似于光栅化渲染中,光栅化状态结构体中的CullMode(剔除模式)变量,通常我们指定RAY_FLAG_CULL_BACK_FACING_TRIANGLES剔除背面三角形即可;
4、第三个参数InstanceInclusionMask是一个位掩码,用于在复杂场景光追渲染时屏蔽一些网格实例,目前我们简单地的设置为~0即可,表示我们渲染所有的实例;
5、第四个参数RayContributionToHitGroupIndex表示当光线命中网格三角形时,调用的命中(hit)Shader Table(Hit函数的列表)中的Shader函数的索引;
6、第五个参数是用于多个几何体光追渲染时,不同几何体对象的命中Shader Table中的索引;
7、第七个参数就是指没有命中时候的Shader Table中的索引;
8、第八和九个参数我们已经介绍过了。
最终在一般的示例中,我们先掌握第1、2、4、7、8、9参数的用法即可,其它参数除了第3个参数要传入特殊的~0值之外,其它的都传入0值即可。
TraceRay函数在理解上建议大家可以想象它是GPU光追的线程函数,在功能上有点类似CreateThread函数,那么对应的线程入口函数可能就是我们后面要介绍的命中函数或者未命中函数,而线程入口参数就是自定义的变量Payload的引用。
同时TraceRay函数是个“同步函数”,即它返回之后其实表示当前的这条光线(第8个参数传入的)的完整追踪过程已经结束了,Payload中的值也计算完毕可以访问使用了。
进一步考虑到命中(Hit)函数或未命中(Miss)函数都有可能再次调用TraceRay函数,那么这个函数就会形成一个复杂多层次递归调用的形式,而这个递归的过程就是光线不断发射、反射、折射、透射等的过程。理论上来讲其递归深度可以是无限的,但实际上一般递归次数也就不到3次左右。或者当光线最终指向光源时递归也就应该终止了。
另一方面从TraceRay函数的功能原理也可以看出,Raytracing Shader要求的强悍计算能力了。
3.5、系统变量内嵌函数(Raytracing HLSL System Value Intrinsics)
“系统变量内嵌函数”,并不是真正意义上的函数,它其实和我们在光栅化Shader,如VS中,定义变量时指定的语义是一个意思(指相同的语义)。比如,定义顶点位置时:float4 m_vPOS:SV_POSITION;其中的SV_POSITION语义就是说m_vPOS是位置变量。而这里则是使用函数的形式替代这个变量定义形式的语义文法,这样一来我们访问系统变量时,就不一定非要定义成变量形式,直接调用函数即可。这样我们不必在Shader函数的输入输出参数中才能关联访问系统变量。最终这使得Shader的编写更加灵活,而可读性也更高。函数化之后我们就可以在Shader函数的任何地方轻松的访问系统变量。而五花八门的自定义系统变量名从此就被统一成了“系统变量内嵌函数”调用。
这也可以形象的理解为将SV_POSITION改成函数SV_POSITION()直接返回位置变量,这样我们就不用自己定义位置变量m_vPOS了。同样我们可以等价的理解为函数DispatchRaysIndex的意思就是定义形如 uint2 index: DispatchRaysIndex这样的一个变量。这是Raytracing Shader中的新的语法变化,请大家深刻理解。
其它的常用的系统变量内嵌函数如下表所示(注意系统变量内嵌函数没有参数,直接名称加括号调用即可):
|
Ray dispatch system values(光线发射系统变量) |
|
|
名称 |
含义描述 |
|
DispatchRaysIndex |
得到当前像素点的X、Y坐标值,取值范围在DispatchRaysDimensions系统变量之内 |
|
DispatchRaysDimensions |
在初始DispatchRays调用中指定的D3D12_DISPATCH_RAYS_DESC结构的宽度、高度和深度值。 |
|
Ray system values(光线(射线)方程系统变量) |
|
|
名称 |
含义描述 |
|
WorldRayOrigin |
当前光线在世界坐标系中的起点位置向量。 |
|
WorldRayDirection |
当前光线在世界坐标系中的方向向量。 |
|
RayTMin |
当前光线(射线)方程中指定的t值的最小下界。 |
|
RayTCurrent |
当前光线(射线)与物体碰撞点的t值,范围在TMin与TMax之间,TMin<=t<=TMax。当t==TMax时,触发的是未命中函数。 |
|
RayFlags |
当前光线的RayFlags标志值,即调用TraceRay时指定的RayFlags值。 |
|
Primitive/object space system values(物体空间系统变量) |
|
|
名称 |
含义描述 |
|
InstanceIndex |
顶级光线跟踪加速结构中当前实例的自动生成索引。 |
|
InstanceID |
顶层结构中的底层加速结构实例上的用户提供的实例标识符。 |
|
PrimitiveIndex |
在底层加速结构实例的几何结构内部自动生成原语的索引。 |
|
ObjectRayOrigin |
当前光线在物体坐标系中的起点 |
|
ObjectRayDirection |
当前光线在物体坐标系中的方向 |
|
ObjectToWorld3x4 |
物体空间到世界空间变换的矩阵(3行4列) |
|
ObjectToWorld4x3 |
物体空间到世界空间变换的矩阵(4行3列) |
|
WorldToObject3x4 |
世界空间到物体空间变换的矩阵(3行4列) |
|
WorldToObject4x3 |
世界空间到物体空间变换的矩阵(4行3列) |
|
Hit-specific system values(特定碰撞系统变量,主要用于Any Hit或Closest Hit等过程) |
|
|
名称 |
含义描述 |
|
HitKind |
作为传递给ReportHit的HitKind参数的返回值。 |
3.6、最近命中(碰撞)函数(Closest Hit)
光线(射线)在通过TraceRay函数发射出去之后,一旦第一次碰撞到物体网格的某个三角形后,光追渲染过程就会调用被称之为最近命中函数的自定义函数。在示例中,它被定义成如下的样子:
[shader("closesthit")]
void MyClosestHitShader(inout RayPayload payload, in MyAttributes attr)
{
float3 hitPosition = HitWorldPosition();
// Get the base index of the triangle's first 16 bit index.
uint indexSizeInBytes = 2;
uint indicesPerTriangle = 3;
uint triangleIndexStride = indicesPerTriangle * indexSizeInBytes;
uint baseIndex = PrimitiveIndex() * triangleIndexStride;
// Load up 3 16 bit indices for the triangle.
const uint3 indices = Load3x16BitIndices(baseIndex);
// Retrieve corresponding vertex normals for the triangle vertices.
float3 vertexNormals[3] = {
g_Vertices[indices[0]].m_vNor,
g_Vertices[indices[1]].m_vNor,
g_Vertices[indices[2]].m_vNor
};
// Compute the triangle's m_vNor.
// This is redundant and done for illustration purposes
// as all the per-vertex normals are the same and match triangle's m_vNor in this sample.
float3 triangleNormal = HitAttribute(vertexNormals, attr);
float4 diffuseColor = CalculateDiffuseLighting(hitPosition, triangleNormal);
float4 color = g_stSceneCB.m_vLightAmbientColor + diffuseColor;
payload.color = color;
}
1、与光线发射函数类似,其语义文法标识是:[shader("closesthit")];即告诉Raytracing Shader编译器、DXR、显卡驱动及GPU后面这个函数就是最近碰撞函数。
2、它的第一个入口参数就是我们刚才讲的Payload自定义变量,那么在我们的例子里就是发出这条光线的像素点的颜色值。而其第二个参数in MyAttributes attr,其原类型是BuiltInTriangleIntersectionAttributes,即碰撞点所属三角形(也可能是别的几何体,但通常是三角形)的重心坐标,它的原始定义如下:
struct BuiltInTriangleIntersectionAttributes
{
float2 barycentrics;
};一般情况下它满足下列方程(假设三角形的三个顶点坐标向量分别是v0、v1、v2):
碰撞点V的位置向量(重心坐标)= v0 + barycentrics.x * (v1-v0) + barycentrics.y* (v2 – v0)。
这个计算代表的具体几何意义如下图所示:

当然通常在实际的Raytracing Shader中我们并不这样计算碰撞点的坐标,而是通过光线(射线)的方程直接计算。而重心坐标主要用来计算碰撞点的法向量,从而方便我们进一步计算光照情况。
3、函数一开始就调用了一个辅助函数HitWorldPosition来计算碰撞点的坐标,该函数定义如下:
float3 HitWorldPosition()
{
return WorldRayOrigin() + RayTCurrent() * WorldRayDirection();
}其实它里面的计算过程就是我们刚才说的使用射线方程计算碰撞点的坐标向量。它里面就是调用了三个“系统变量内嵌函数”。实质上它就是方程:碰撞点=光线起点向量 + 碰撞点t值*光线方向向量,因为碰撞点必定在光线(射线)上。当然此处的碰撞点t值必定在我们发射光线时指定的TMin和TMax之间。这里需要注意的一个细节就是当实际碰撞点的t值超过了TMax时,实质上光追渲染过程是不会调用命中函数的,而是去调用未命中函数(Miss),含义就是说碰撞点实质上超出了我们规定的射线的最大射程,因此为了正确的光追效果建议设置较大的TMax值。
4、有了碰撞点位置的坐标向量之后,命中函数中接着使用“系统变量内嵌函数” PrimitiveIndex获得当前碰撞网格索引数组中,当前被碰撞三角形的序号,接着根据我们传递的索引数组的格式大小(3*sizeof(UINT16)),计算得到实际对应的索引数组中的偏移位置,再通过工具方法Load3x16BitIndices从网格索引数组中读取出三角形三个顶点的索引,然后根据索引读取顶点数组得到三角形三个顶点数据(g_Vertices[indices[0]],g_Vertices[indices[1]],g_Vertices[indices[2]])。接着根据我们刚才介绍的重心坐标调用工具函数HitAttribute计算出碰撞点的法向量,这个法向量就是三角形各顶点法向量的以重心坐标为权重的算数平均值,是一个均匀插值结果。实质上在更加真实的光追渲染过程中,这里其实需要计算出法线贴图的纹理坐标,然后从法线贴图中读取碰撞点处的法线,因为真实物体表面并不是均匀光滑的。这与在传统的光栅化渲染中使用法线贴图的方法是一致的。同样的我也假设你对这一个方法已经了如指掌。
5、有了碰撞点的位置坐标向量和法向量,接着调用辅助函数CalculateDiffuseLighting计算出光源位置到碰撞点的向量与碰撞点法向量的点积,并取大于0的值,因为负值表示二者夹角大于90度了。然后再用这个点积*物体表面的反光率参数m_vAlbedo*光源的漫反射光颜色参数m_vLightDiffuseColor,得到碰撞点的漫反射颜色值。这个计算其实也是与光栅化渲染中漫反射颜色计算过程一致。
6、最后碰撞点对应像素颜色值,就设定为我们计算的漫反射颜色值+环境光颜色(float4 color = g_stSceneCB.m_vLightAmbientColor + diffuseColor;)。作为进一步的练习,大家可以在此基础上扩展计算下高光反射(镜面反射)的颜色值,彻底模拟出光栅化渲染中像素颜色值=镜面高光+漫反射光+环境光的经典光照模型。
3.7、未命中函数(Miss)
当光线(射线)不与任何场景中的物体碰撞或者碰撞点的t值大于射线方程的TMax值时,光追渲染过程就会调用称之为未命中函数的Shader方法。在我们的例子中该方法定义如下:
[shader("miss")]
void MyMissShader(inout RayPayload payload)
{
float4 background = float4(0.2f, 0.5f, 1.0f, 1.0f);
payload.color = background;
}它的含义很简单就是为任何没有碰撞到物体光线的像素点设置一个天蓝色的默认颜色。
通常这个函数中我们就实现一个经典的“天空盒”3D纹理采样或像这里一样简单的返回一个默认背景色即可。
4、Raytracing Shader编译和Shader中包含头文件的技巧
在之前的教程示例中,我都建议大家使用代码中调用编译函数的方法来编译Shader,这样主要是为了大家将来编写内置工具的方便。但是目前我还没有调通Raytracing Shader的纯代码函数编译方法,我也正在想办法加紧研究微软的GitHub项目DirectXShaderCompiler,后续的教程中我争取将代码中编译的方法试验通后分享给大家。现在我们暂时使用fxc.exe编译工具编译的方法。
4.1、Raytracing Shader的编译
在VS2019中已经嵌入了Shader的编译工具的命令行编译方式,只要我们定义一个Shader文件(扩展名最好是HLSL),之后我们就可以在项目中指定使用HLSL编译器编译该文件。方法是在VS2019中,解决方案面板中找到Shader文件,然后点击右键,弹出菜单如下:

然后点击属性菜单项,弹出文件的属性对话框如下:

设定项类型为HLSL编译器,紧接着选定左边配置属性中的HLSL编译器项,将其展开如下:

然后将右边的属性项改成如图所示:

其中:着色器类型设定为/Lib,含义是将整个Shader编译成类似一个静态库的类型,它里面包含若干个Shander函数的编译后的机器码,这与编译传统的光栅化Shader不同,传统的光栅化Shader必须明确Shader对应的阶段,同时每个阶段都必须明确指定一个入口点名称(就是Shader的主函数)。lib形式是Raytracing特有的形式,因为里面包含多个函数入口及函数体,所以不用再指定入口点名称。同时这里我们指定的着色器模型是6.3,至少指定必须是6.1,因为从6.1开始引入了Raytracing Shader,指定6.3对应的Windows SDK版本必须是17763,因为fxc编译器现在包含在Windows SDK中。
接下来我们需要指定的Shader编译选项是生成Shader代码的C/C++包含文件,我们点击属性页面坐标的“输出文件”选项,然后设置如下图所示:

这样Raytracing Shader编译后就会生成一个C/C++头文件,这个头文件中就会以十六进制字符数组变量的形式,将Shader编译后的二进制码定义为一个超大的数组,这样我们在C/C++代码中包含这个头文件之后,Shader的二进制代码就可以直接利用g_p%(Filename)的形式来直接访问了,我们示例代码中这个变量经过宏替换后名为:g_pRaytracing。最终这个头文件看起来像下面这个样子:

4.2、Shader中包含头文件的技巧
在我们之前系列教程的示例代码中,我们会发现顶点数据结构的定义往往需要在Shader 和C/C++代码中分别定义,而且还必须保持一致,这对于稍微复杂点的项目来说都是不可容忍的。
本教程中因为我们直接引用了微软DXR示例中的Shader,所以也保留了它解决这一问题的方法,那就是定义两个辅助头文件,分别是:HlslCompat.h和RayTracingHlslCompat.h。其中HlslCompat.h很简单,它的目的就是通过typedef的方法将Shader和C/C++中的向量数据类型进行一个兼容定义如下:
#ifndef HLSLCOMPAT_H
#define HLSLCOMPAT_H
typedef float2 XMFLOAT2;
typedef float3 XMFLOAT3;
typedef float4 XMFLOAT4;
typedef float4 XMVECTOR;
typedef float4x4 XMMATRIX;
typedef uint UINT;
#endif // HLSLCOMPAT_H接着在RayTracingHlslCompat.h中像下面这样条件包含HlslCompat.h头文件,并定义我们需要的顶点结构、常量缓冲结构等:
#ifndef RAYTRACINGHLSLCOMPAT_H
#define RAYTRACINGHLSLCOMPAT_H
#ifdef HLSL
#include "HlslCompat.h"
#else
using namespace DirectX;
// Shader will use byte encoding to access indices.
typedef UINT16 GRS_TYPE_INDEX;
#endif
struct ST_SCENE_CONSANTBUFFER
{
XMMATRIX m_mxP2W;
XMVECTOR m_vCameraPos;
XMVECTOR m_vLightPos;
XMVECTOR m_vLightAmbientColor;
XMVECTOR m_vLightDiffuseColor;
};
struct ST_MODULE_CONSANTBUFFER
{
XMFLOAT4 m_vAlbedo;
};
// 顶点结构
struct ST_GRS_VERTEX
{
XMFLOAT4 m_vPos; //Position
XMFLOAT2 m_vTex; //Texcoord
XMFLOAT3 m_vNor; //Normal
};
#endif // RAYTRACINGHLSLCOMPAT_H因为HLSL宏是在fxc编译时预定义的一个宏,所以当RayTracingHlslCompat.h头文件被包含在Shader文件中时,HlslCompat.h就被包含进来了,这样Shader编译器就理解XMFLOAT2、XMFLOAT3、XMFLOAT4等变量为Shader数据类型float2、float3、float4等。
而在C/C++文件中包含RayTracingHlslCompat.h头文件,在编译时因为没有HLSL预定义宏,所以XMFLOAT2、XMFLOAT3、XMFLOAT4等变量含义就是原始的DirectXMath.h中的对应向量类类型。
最终通过这样的技巧方法,我们就只需要在RayTracingHlslCompat.h这一个头文件中维护顶点数据类型结构体、常量数据类型结构体等即可,就不需要分开定义在Shader和C/C++两处。
当然这个方法的使用最终得益于独立的fxc Shader编译器,而我们之前在代码中调用D3DCompileFromFile函数编译的方法不能简单的使用这个技巧,但是这也是可以用的,之后的教程中我找机会为大家补上怎么用D3DCompileFromFile函数来使用这一方法。
最后建议大家扩展HlslCompat.h中的兼容类型定义,使Shader的数据类型与DirectXMath库中的变量完全对应,方便以后使用。
(未完待续,预计伟大祖国生日过后继续发布,敬请期待,谢谢!)







![[转]我国CAD软件产业亟待研究现状采取对策-卡核](https://www.caxkernel.com/wp-content/uploads/2024/07/frc-f080b20a9340c1a89c731029cb163f6a-212x300.png)







暂无评论内容