
目录
1、前言
在《外篇一》教程中,已经交代了为什么使用Assimp库来导入模型。这一篇中就先来个热身看看具体怎么调用Assimp库。
其实说起用Assimp库,开始我不是很了解这个库,后来实在是因为导入模型以及动画数据匮乏的问题,所以导致我必须要仔细的琢磨一下这个库。
在使用的过程中,还算顺利,遇到几个坑,但都不大,主要问题就是那个著名的“你习惯左手、还是右手”的问题,其实就是个矩阵转置以及左乘还是右乘的问题,如果线性代数或3D数学基本功扎实的话,这基本也算不上什么问题。(当然这要求你能够左手D3D、右手OpenGL,左右开弓!左手右手一个慢动作~~! 来左边儿跟我一起画个龙,在你右边儿画一道彩虹~~)
另外因为在我的职业生涯中,有几年是与数据打交道的,所以这篇教程就先做一个裸看数据的教程,即将所有导入后的3D模型数据打印到命令行窗口的方式,核心的目的是让大家理解Assimp导入的数据及其结构。
在理解上大家可以把Assimp解析文件导入后的数据理解为一个中间结果,这有点像现代很多编译器将源文件编译为称之为中间代码IR(Intermediate Representation)的中间结果,我们可以称之为ID(Intermediate Data),再由具体的渲染器去进一步解析转换,然后去渲染的方式。基于这样的理解,所以首先就需要搞清楚这个中间结果数据到底是什么样的,因此本章教程,我就干脆更返璞归真一点,直接用最简单的命令行方式,把所有导入的中间数据都显示一遍,让大家对3D模型中的数据以及数据结构有个本质上的认识。同时也为大家提供一个简便的数据看板,以后还可以用来当作调试输出来进一步观察网格数据的变化,从而从纯数据的角度掌握模型网格、3D骨骼动画数据变换的根本规律!
当然如果搞明白了3D模型数据及结构,大家还可以用一个“恐怖”的联想来理解整个3D渲染的过程,其实就是一个“画皮”的过程,所以所谓的渲染就是用“好看的皮囊包裹数据”,然后用一副“白骨精”的骨架撑起这幅皮囊让它动起来,形成3D动画(骨骼动画)。这个过程在Unity3D中被形象的称之为“阿凡达(Avatar)”系统(当然你应该看过这部电影了,知道我在说什么,这不是广告!),其含义与这里所隐喻的“白骨精”和“画皮”的意思是相通的(你也该深深的感受到了东西方文化的差异以及共通的东西!)。
本章示例代码已全部上传至Github:GRSD3D12Sample/16-Assimp_Data_Display
无法访问Github时可以到gitee:16-Assimp_Data_Display – 码云 – 开源中国 (gitee.com)
或:16-Assimp_Data_Display – 码云 – 开源中国 (gitee.com)
2、Assimp使用简介
Assimp库因为需要兼容导入各种格式的模型文件,而这些模型文件其实大多数都是面向OpenGL的,所以它导入的数据基本都是右手坐标系的,当然通过标志可以转换为D3D的左手坐标系,但是如果是最终用于D3D那么所有的矩阵还需要自己转置一下,并使用D3D的矩阵右乘行向量的方式进行坐标变换计算。
另外在使用的过程中,请各位一定注意在需要导入的模型文件名称及其路径中任何位置不要出现中文或者过长的名字,因为Assimp发现中文文件名直接就报错了,我估计是因为它内部使用了古老的C库函数操作文件所致,毕竟它是要考虑跨平台的库,所以这也不是什么大问题,把中文改成英文,或者拼音就可以了。
3、Assimp头文件和库文件引入
编译好Assimp之后,就可以在我们的程序中引入并使用了。当然因为Assimp是在Github上的一个开源项目,所以其实也可以使用Git子模块的方式引入,建议比较正式的项目中都使用Git子模块引用的方式,在我的示例里面就不这样用了。
通常引用任何第三方库到到C/C++项目中基本做法就是找到Include文件和Lib文件,在Assimp中Include在如下的路径中:

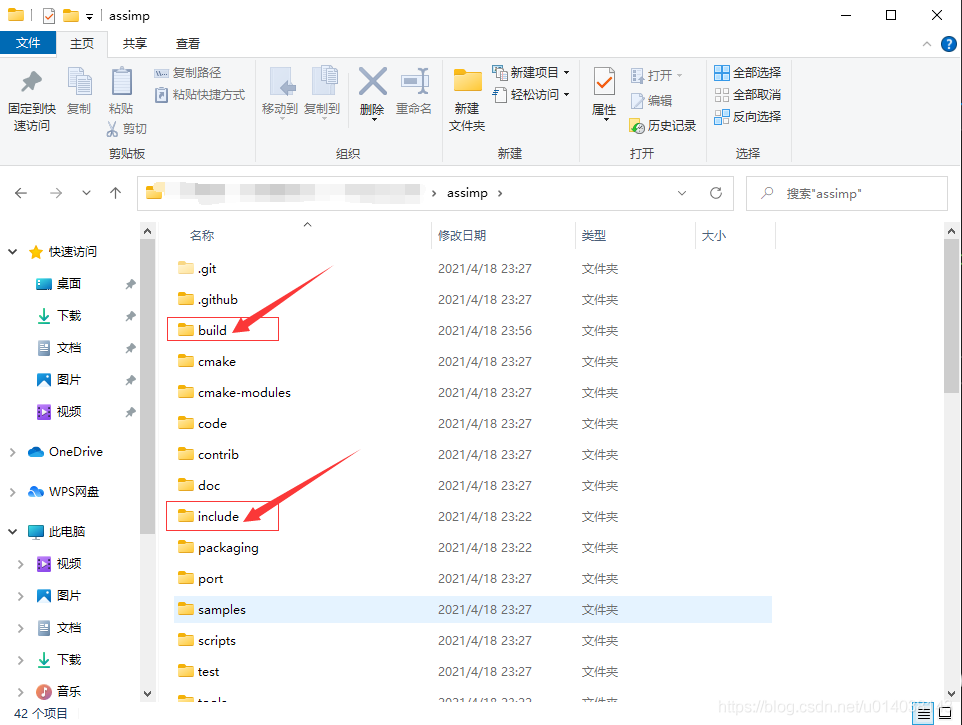
在项目中使用assimp时,首先需要复制include目录,注意直接复制include目录,不要进入目录里面复制assimp子文件夹,因为它这个工程的包含关系比较独特,所以必须放在assimp子文件夹中;
接着打开build目录,在里面还有一个include,一样复制到刚才的include平级目录中,在这个include中主要有个config.h文件是编译时生成的,需要放到assimp的目录中去。

复制到项目中之后如下:

接着在include的平级目录创建一个lib文件夹,并且将build目录中code下的Debug目录中的所有文件复制到lib文件中:

复制后文件如下:

在本教程的示例中,最终assimp的include和lib文件夹摆放如下:

当然这种摆放方式不是被推荐的方式,一般正式的项目中都会再建一个子文件夹,比如常见的叫做ThirdParty目录,在里面按照引用的组件分文件夹摆放相应的头文件和库文件,我们这里只是为了简单示例所以就直接丢在了整个解决方案的根目录下,因为这个系列还只是教程,拢共也不会引用多少第三方库,目前只有这一个assimp是我们需要的。正式的引擎中请不要这样做,防止发生不必要的麻烦。
接着就需要我们在项目属性中指定这两个文件夹了,此时在需要使用assimp的项目节点上打开属性对话框,操作如下:

然后在弹出的对话框中做如下的操作:

在包含目录中如下设置:


接着如法炮制设置lib的路径:

最后需要在项目属性中添加一个生成前事件如下:

所有操作都选确定结束后,我们的项目就可以正常的包含头文件和引用lib文件了。这里需要提醒大家的是两点:
1、对于包含的头文件路径或库文件路径,请尽量使用这里说的“宏”方法来编写路径公式,这样当项目在挪动路径,或变动位置时,不至于路径出错,尽量避免使用绝对路径。并且相关的头文件库文件位置都尽量按刚才说的方法放到第三方库的目录中,并最终放置在解决方案目录的根目录下,这样所有的代码位置就都可以随意的挪动了;
2、在示例中,无论是Debug还是Release按这里的设置都会引用到assimp的Debug版的lib文件和动态库,大家如果愿意的话就自行按照前一个教程中所说的方法自行编译Release版的lib和dll出来,然后用相同的方法,在项目的Release配置中引用Release版的文件,这里就不再啰嗦的做这个事情了;一法通,万法通!
最后在项目的CPP文件中加入如下的代码,即可使用assimp库了:
#include <assimp/Importer.hpp> // 导入器在该头文件中定义
#include <assimp/scene.h> // 读取到的模型数据都放在scene中
#include <assimp/postprocess.h>
#pragma comment(lib, "assimp-vc142-mtd.lib")
4、Import模型文件
引入了assimp库之后,那么接着就是在代码中调用assimp的类和api来导入想要的3D模型文件了。由于assimp封装的简洁性,通常这只需要两行代码即可:
Assimp::Importer aiImporter;
// 读取模型文件
const aiScene* pModel = aiImporter.ReadFile(pXFile, ASSIMP_LOAD_FLAGS);
其中pXFile是一个文件完整路径名,并且是单字节字符集的,按照之前提示的,这个文件路径中千万千万不要有任何中文字符在里面,否则assimp都会导入失败。(本来我想找下这个问题,可惜由于时间关系,还是算了,其实很多开源库对中文支持都是很不友好的,感觉都2020年代了,很多程序员还不知道这世上有个unicode。用这些库的时候,老是让我感觉穿越回了20多年前的DOS编程时代。)
ASSIMP_LOAD_FLAGS参数是导入3D模型文件时需要做的处理,在assimp中有一堆标志(是一个枚举值,详细的下章再讲。)可以对模型网格等数据做丰富的处理,这些处理在assimp中都被称为后处理(Post Process),注意这与渲染中的后处理完全是两码事,不要混为一谈。其实这里的基于网格(Mesh)的后处理,是计算机图形学的一个重要分支“计算机几何学”的研究领域,也是CAD等大型复杂几何软件中的一个关键应用领域。而在使用assimp时,只需要设置几个位或的标志值即可执行想要的处理操作,不需要过多的关心具体的算法和计算过程,由此也可以看出并感受到assimp的功能其实还是比较强悍的。
最终导入后的模型数据包括网格、骨骼、材质、动画、灯光、摄像机等都在一个专门的类aiScene的实例对象中,在示例代码中定义对象为aiScene* pModel。需要注意的是这个对象最终是个常量对象,因为assimp在导入时做了很多内存分配的工作,为了不把这些繁琐的内存操作暴露出来,所以它刻意让导出的对象为常量,即调用时只读,来防止调用者错误的内存操作而造成任何的问题,同时这样的设计,也使得调用者根本不用关心内存管理的问题,从而降低了使用的难度和复杂度。这也是一种常见的C/C++库封装的思路。但这种设计只是一个“君子协议”,并不能保证内存完全安全,毕竟直接可以访问其成员指针,不能完全保证不被改写或误删除等,当然基于对它是个ID的认识,大概不会有人会去这样操作。
模型导入成功后,Assimp::Importer::ReadFile方法就返回一个非空的有效的aiScene对象,假如失败则会返回NULL,此时可以使用Assimp::Importer类的对象aiImporter的GetErrorString()获得详细的错误原因。
Assimp::Importer aiImporter;
// 读取x文件
const aiScene* pModel = aiImporter.ReadFile(pXFile, ASSIMP_LOAD_FLAGS);
if (nullptr == pModel)
{
GRSPrintfA("无法解析文件(%s):%s (%d)\\n", pXFile, aiImporter.GetErrorString(), ::GetLastError());
AtlThrowLastWin32();
}
5、aiScene基本数据结构及遍历
导入之后,关于模型中所有的中间数据就会缓存在aiScene对象中,其结构按之前所说,是一种中间结构(ID),正式使用时,一般需要按照对应的渲染API(OpenGL、D3D、Vulkan等)做一些简单解析。因此,要解析这些数据,首先就必须要精确掌握其结构。首先我们就来看一下aiScene中牵涉到的类及对应关系,实际的理解中,因为我过去搞过数据分析的原因,所以我在理解上比较喜欢把它整个理解为一个ORM(Object Relational Mapping)模式。基于这个理解,就不难理解为什么assimp类的设计中所有成员变量都可以自由访问了,这是因为大多数纯ORM为了省去大量无聊的Set、Get成员函数,索性就把其成员变量完全开放供调用程序来读写,并且ORM一般假设调用者对数据结构及逻辑关系了如指掌。
基于这样的认识,那么首先就让我们来看看它的类图,以便深入了解assimp中的数据结构。
5.1、Assimp类图及关系
assimp中读取模型数据部分的主要类关系及数据结构如下图所示:

从图中可以看出以下几点:
1、从其类图中可以看到,这是一个典型的ORM结构,解析是非常方便的,同时也很方便转存为自定义的格式,甚至可以转存到数据库中;
2、类之间主要的关系都是聚合关系,既所有的类都有相同的生命周期,因此保持aiScene类的对象的存活,就可以一直读取其中的数据;注意请不要直接去修改里面的任何数据!!!只读即可。
3、图中还有些类我就没有进一步再展开画了,掌握到这里对我们读取和解析模型数据来说已经足够了;
4、图中比较核心的类就是aiMesh类,它的内容是比较好理解的,无非就是每个网格的顶点数据和索引数据,其中索引数据隐藏在aiFace中;顶点数据中,就包含位置、法线、可选的切线、副切线、以及可能是多通道的颜色、纹理坐标等;这些基本数据都比较好理解,这里以及后文中就不再赘述了;
5、材质Material信息的存储比较特殊,在assimp中使用了较复杂的属性链表形式,解析上有点麻烦,在aiMaterial类中提供了非正交的一组方法来读取属性,但是没有遍历和枚举全部属性键值的方法;本章例子中索性直接遍历其属性数组进行读取解析;
6、类图中没有显示类的方法,这可以通过大家读取其源代码来理解。assimp中类的方法都不复杂,比较简单易懂,并且类中的数据几乎都是public的,可以直接读取,所以图中就没有再啰嗦的绘制其方法了;
7、aiNode类形成了一个树形结构,其实里面主要存储的就是网格的骨骼信息,它形成了一个典型的Composition设计模式;当然这棵树可能也是用来表达子网格间的相对关系的,但最常用的还是用作表达模型的骨骼。
8、一般情况下aiScene中都会包含至少一个aiNode根节点和一个aiMesh数据,但不都是这样,导入数据后需要进行判断;
最后要提醒大家的是,UML图尤其是类图的画法也是现代程序员必须掌握的硬核技能之一,所以要完全明白图中的意义,就要学会UML图的绘制方法。当然这个不是本系列文章中的内容,就不再赘述了。
另外因为本章示例基本就是遍历数据的过程,没有特别的加工处理,所以除了较重点的结构解析的几个地方外,其它的就不会再过多啰嗦了。请大家自行阅读源码理解即可。
5.2、aiScene遍历
掌握了基本的类结构,就可以遍历aiScene中的数据了。本章示例中在读取模型文件成功后,就直接按照次序以此读取和列印aiScene所包含的所有对象及数据。其中最重要的是aiNode、aiMesh两个数据对象,当模型中有动画时,aiAnimation也是很重要的对象。
5.3、网格数据(aiMesh)
在本章示例中,程序在读取完aiScene后,第一步就是调用HasMesh方法判断对象中是否有Mesh数据,如果有就循环遍历每一个Mesh。需要提醒各位的是,一般情况下,网格文件中通常不止包含一个Mesh对象,而是会有多个。这样做的目的,一是可以将模型中的不同部分适用不同的Mesh来设计,并配以不同的动画、材质、等信息,从而可以方便美工设计出较复杂的3D模型。
主线程中遍历Mesh的代码如下:
CHAR pXFile[MAX_PATH] = {};
StringCchPrintfA(pXFile, MAX_PATH, "%Assets\\\\The3DModel\\\\hero.x", pszAppPathA);
//......
Assimp::Importer aiImporter;
// 读取x文件
const aiScene* pModel = aiImporter.ReadFile(pXFile, ASSIMP_LOAD_FLAGS);
//......
if ( pModel->HasMeshes() )
{
GRSPrintfW(L"\\n网格:\\nMesh Count[%u]:\\n", pModel->mNumMeshes);
GRSConsolePause();
// 网格
const aiMesh* paiSubMesh = nullptr;
for (UINT i = 0; i < pModel->mNumMeshes; i++)
{
paiSubMesh = pModel->mMeshes[i];
ShowMesh(i + 1, paiSubMesh);
GRSConsolePause();
}
}
else
{
GRSPrintfW(L"该模型中没有网格信息!\\n");
}
其中主要用ShowMesh来遍历aiMesh中的数据,因为这个函数比较冗长乏味,我就不粘贴全部代码了,大家自行下载阅读即可,我主要讲一下重要的骨骼数据的结构,遍历骨骼数据的代码如下:
if (paiMesh->HasBones())
{
GRSPrintfW(L"\\nBones[%u]:\\n", paiMesh->mNumBones);
for (UINT i = 0; i < paiMesh->mNumBones; i++)
{
aiBone* paiBone = paiMesh->mBones[i];
GRSPrintfA("\\nBone[%u]:\\"%s\\" - 逆绑定位姿矩阵(Inverse bind pose matrix):\\n"
, i
, paiBone->mName.C_Str()
);
GRSPrintfMX(paiBone->mOffsetMatrix);
GRSPrintfW(L"\\nWeights[%u]:\\n", paiBone->mNumWeights);
for (UINT j = 0; j < paiBone->mNumWeights; j++)
{
GRSPrintfW(L"[%4u](%4u,%11.6f), "
, j
, paiBone->mWeights[j].mVertexId
, paiBone->mWeights[j].mWeight);
if (((j + 1) % 10) == 0)
{
GRSPrintfW(L"\\n");
}
}
GRSPrintfW(L"\\n\\n");
}
GRSPrintfW(L"\\n");
}
aiBone类中存储的就是3D骨骼动画的顶点对应的骨骼数据了,在assimp中,与在一般的Vertex Shader中定义和关联的方式不同,这里是按照每根骨头关联那些顶点来倒放的,这样极大的降低了冗余数据,因为不需要在每个顶点中都存放骨骼数据,所以就不会造成骨骼数据重复或者说本身就没关联的骨骼的顶点也需要存储空的骨骼数据。另外这样的设计也方便将每个骨骼相对于网格的几何中心或重心的偏移矩阵单独存储在骨骼对象中,在aiBone类中这就是成员mOffsetMatrix,该矩阵也被成为“逆绑定位姿矩阵”(inverse-bind matrix,or inverse bind pose matrix.)。然后数组mWeights中存储的两个值就分别对应被影响的顶点的索引mVertexId,以及影响的权重mWeight。
而在实际渲染时,需要每个顶点都带有关联的骨骼以及受影响的权重值,即跟assimp中解析出来的方式正好相反。这相当于一个数据查询SQL中的join操作,即把Bone信息左连接到顶点数据上。
示例运行后,Bone数据输出如下:

最后需要补充的是,在Assimp中,顶点索引数据是被放在一个aiFace(面)的类中,通常有些模型文件中导入的面不一定都是三角形,所以每个面关联的顶点可能不止3个,这对于OpenGL的渲染来说没什么,因为它本身就支持很多种图元类型,但是对于D3D渲染来说,就比较麻烦了,当发现某个模型中有面的索引数量不等于3,也就是有不是纯三角形网格时,就需要在导入时加入“aiProcess_Triangulate”后处理标志来做转换了。这种差异不是说OpenGL就比D3D强大,而是因为实质上现在D3D接口更加接近显卡,或者说更接近于“面向显卡驱动”编程,拥有更高的灵活性和性能,然后把所有可能需要算法支撑的功能都删除掉,交给程序开发人员去实现。这就好像C语言中将内存管理都交给程序员去完成,并不提供垃圾回收机制一样。这一切都是为了高度的灵活性和性能,当然对于开发人员的要求也就更高。
示例程序运行后,输出的aiFace信息如下:

每个aiFace中都存储了一个面关联的顶点的索引数组,当将这些索引都串存为一个统一的数组就是渲染时需要的索引数组。
5.4、材质数据(aiMaterial)
在一个模型文件中,最重要的美术数据就是材质信息了。在assimp中,材质的信息以一种特殊的属性列表的形式存储在aiMaterail类中。
通常现在的模型材质分为两大类,一类是基于传统光照模型的材质,其中只是简单的漫反射值、镜面反射值、高光系数等参数,另一类是基于PBR的材质,其中存储的就是金属度、粗糙度等,这类PBR被称为金属工作流PBR的参数,还有一类PBR也是基于镜面反射系数、漫反射系数的镜面反射/光泽度工作流,两种PBR工作流可以互相转换,目前比较主流的是金属工作流。
无论那种具体的材质,其参数可以是一个值,也可以是一副纹理,当是一个值的时候,表示当前关联的网格在渲染时,所有该参数都只取这一个值,如果是纹理时,那就是具体在每个像素渲染时取该值。目前我手头能找到的文件基本都是基于传统光照模型的3D模型,经过assimp加载解析后,材质数据大致像下面这样:


这里需要注意的是具体在读取材质信息时,需要使用aiMaterial中的Get系列方法,以及aiMesh中的辅助方法。在aiMaterial头文件中有一组宏用于定义这些键名称,可以利用这些宏以及对应的辅助方法来得到具体的每个属性:
// ---------------------------------------------------------------------------
// Pure key names for all texture-related properties
//! @cond MATS_DOC_FULL
#define _AI_MATKEY_TEXTURE_BASE "$tex.file"
#define _AI_MATKEY_UVWSRC_BASE "$tex.uvwsrc"
#define _AI_MATKEY_TEXOP_BASE "$tex.op"
#define _AI_MATKEY_MAPPING_BASE "$tex.mapping"
#define _AI_MATKEY_TEXBLEND_BASE "$tex.blend"
#define _AI_MATKEY_MAPPINGMODE_U_BASE "$tex.mapmodeu"
#define _AI_MATKEY_MAPPINGMODE_V_BASE "$tex.mapmodev"
#define _AI_MATKEY_TEXMAP_AXIS_BASE "$tex.mapaxis"
#define _AI_MATKEY_UVTRANSFORM_BASE "$tex.uvtrafo"
#define _AI_MATKEY_TEXFLAGS_BASE "$tex.flags"
//! @endcond
具体的读取材质属性值的方法都在同一个头文件中,大家可以自行阅读源代码去理解,因为这些函数都很简单,有了键值就是按照类型读取对应的键值即可,此处就不再浪费篇幅啰嗦了。
5.5、骨骼结构(aiNode)
对于一般的模型文件来说,在assimp导入之后的aiScene对象中至少都会有一个aiNode* mRootNode节点,在没有骨骼的情况下,这个根节点中就简单的存储了一个模型相对于世界坐标系的变换矩阵,或者直白的说,就是表示整个模型包括子网格在世界空间中如何摆放,通常这个矩阵只是一个简单的单位矩阵,实际应用中,至于导入的模型完全是调用程序如游戏场景来决定的,这个矩阵实际上意义不大。
而在具有骨骼绑定的模型数据中,从这个根节点出发,就可以形成一个骨骼树,在示例程序中,为了更直观,将这颗树在命令行窗口中以树形结构列印了出来,如下:

图中需要注意的是:
1、每个节点中的矩阵,其含义是该骨骼相对于模型空间的坐标原点(往往是几何中心或重心)的变换,包括位移旋转缩放等的复合;
2、“匿名”的节点实质是中间过渡节点,不会关联具体的动画帧数据,只是为了方便使其子节点做统一变换;
3、这些骨骼中的变换矩阵只有当节点匿名或者没有找到对应的动画帧(后面会有描述)时才有意义,否则就会被动画通道中的SQT联合变换替换;默认情况下,用这套矩阵显示出来的是模型静态摆放情况下的一个姿势;
在aiNode中,除了变换矩阵外,重要的数据就是Composition模式需要的子节点指针数组aiNode** mChildren,另外为了方便遍历其中还存储了指向当前节点父节点的指针aiNode* mParent。当然这种定义是一个简化的Composition模式,即没有采用抽象基类的设计,也没有使用容器类来存储子节点,更没有提供复杂的遍历方法,也没有使用观察者模式的设计。只是简单的形成了树形的数据结构,这样的设计可以理解为一种极简主义风格,没有优劣之分,这也是一开始称之为一种中间数据的原因之一,它是比较符合ORM的设计理念的。当然最终要提醒各位的是,这看上去极简的设计,其实更需要极高的设计艺术和对C++语言及数据结构极其深刻的理解。我认为这是一种极显功力的设计理念,值得学习。因为大道至简!
最后在aiNode里还存储了被关联和影响的Mesh对象的索引数组和另一组Metadata,这些都用于更复杂的骨骼动画的场景,本示例中对这组Metadata就没有再进一步解析显示了,大家可以根据已有的代码自行添加显示这组Metadata的代码。
5.6、动画数据(aiAnimation)
对于导入3D模型来说,除了基本的网格、材质,以及重要的骨骼信息外,剩下最重要的就是要导入和解析关键帧动画信息了。在assimp中,这些关键帧动画是按照不同的动作并依据不同的骨骼组织成多条通道,存储在aiAnimation组成的数组里。
具体的,每个aiAnimation存储一套完整的动作,比如某个人物模型的走动就是一个动作,然后在每个aiAnimation中按照骨骼及对应关键帧形成通道数组aiNodeAnim** mChannels存储在aiAnimation的对象中。示例中,按照每个动作,及其内部的通道顺序的列印了所有的关键帧数据,如下:
 其中每个通道都有一个名称,该名称就对应同名的骨骼,然后每个通道中,有三组关键帧数据,就是骨骼动画中经典的SQT变换数据(Scala、Quaternion、Transformation),每组数据以一个关键帧时间点为届。具体动画的详细解算将放在下一讲,这一讲中重点是大家搞明白数据的存放方式和数据结构即可。
其中每个通道都有一个名称,该名称就对应同名的骨骼,然后每个通道中,有三组关键帧数据,就是骨骼动画中经典的SQT变换数据(Scala、Quaternion、Transformation),每组数据以一个关键帧时间点为届。具体动画的详细解算将放在下一讲,这一讲中重点是大家搞明白数据的存放方式和数据结构即可。
5.7、assimp中骨骼动画数据的总结
至此我们应该可以发现,骨骼动画数据在Assimp中被分解成了三个部分:
第一部分在aiMash中存储为aiBone数组,主要存储的是骨骼的逆位姿矩阵和被关联和影响的顶点索引,以及影响的权重;
第二部分以树状结构存储在aiScene的aiNode* mRootNode成员极其子节点中,主要存储的就是骨骼间的关联关系,主要就是树形结构;
第三部分就是关键帧动画数据,主要存贮在aiScene对象的aiAnimation对象中,并且是以经典的SQT变换形式存储的;
三部分数据间主要的关联关系就是依靠个对象或子对象中的mName成员,也就是说骨骼的名称是将这三部分数据串联起来形成骨骼动画的关键线索。具体的3D动画数据的解析、变换、动画渲染,将放到下一讲中继续详细介绍,这里是让大家先对数据本身有一个基本的认识,防止因为一次性的学习跨度太大,而造成学习效果不佳的结果。
5.8、assimp中的纹理
一般的3D模型,其纹理文件都是单独以独立文件形式存储的,一是为了使整个模型文件体积缩小,二是为了平面美工可以方便的修改纹理及材质纹理,所以这导致最终在aiScene中只有材质数据中存储了对应的纹理文件的名称,而其内嵌的纹理数组中往往是没有数据的,因此在本章示例中,就没有再进一步去解读内嵌纹理数据了。这里也就不在赘述了。下一讲将介绍如何利用assimp本身的方法正确的读取到对应纹理文件名称的方法。
6、命令行操作方法说明
因为本章示例中主要是基于命令行输出数据,所以用到了大量的命令行窗口操作。这些方法虽然表面上看上去对基于窗口及D3D或OpenGL渲染的3D程序来说没有大的意义,但是这些方法完全可以用于生成一个调试窗口,因此学习一下其理念也是有现实意义的。在这里重点介绍一下遍历骨骼树的时候显示的那段递归代码,在本示例中这段代码如下:
void TraverseNodeTree( const aiNode* pNode, int iBlank )
{
GRSPrintBlank( iBlank );
int iY = GRSGetConsoleCurrentY();
//填充不连续的列
if ( pNode->mParent )
{//有父节点
aiNode** pBrother = pNode->mParent->mChildren;//兄弟节点列表
UINT nPos = 0;
for ( nPos = 0; nPos < pNode->mParent->mNumChildren; nPos++ )
{//查找节点在兄弟列表的位置,当前节点肯定在父节点的兄弟列表中
if ( pNode == pNode->mParent->mChildren[nPos] )
{
break;
}
}
int iRow = 0;
SHORT sLine = 0;
if ( 0 != nPos )
{//不是第一个兄弟
UINT nPrev = --nPos;
if ( GRSFindConsoleLine( (void*) pNode->mParent->mChildren[nPrev], sLine ) )
{
iRow = iY - sLine - 1;
}
}
else
{// 第一个兄弟 找父亲行
if ( GRSFindConsoleLine( (void*) pNode->mParent, sLine ) )
{
iRow = iY - sLine - 1;
}
}
GRSPushConsoleCursor();//保存光标位置
while ( iRow-- )
{//不停上移动光标,输出|
GRSMoveConsoleCursor( 0, -1 );//上移
GRSPrintfA( "|" );//打印|
GRSMoveConsoleCursor( -1, 0 );//左移回复光标位置
}
GRSPopConsoleCursor();//恢复光标位置
}
GRSSaveConsoleLine( (void*) pNode, iY );
GRSPrintfA( "+――Name:\\"%s\\", Childs[%u]"
, ( pNode->mName.length > 0 ) ? pNode->mName.C_Str() : GRS_NAME_ANONYMITY
, pNode->mNumChildren
, pNode->mNumMeshes );
if ( pNode->mNumMeshes > 0 )
{
GRSPrintfW( L", Affect Meshs Count[%u]:{"
, pNode->mNumMeshes );
for ( UINT i = 0; i < pNode->mNumMeshes; i++ )
{
GRSPrintfW( L"Mesh[%u] ", pNode->mMeshes[i] );
}
GRSPrintfW( L"}" );
}
GRSPrintfW( L", Node Transformation:\\n\\n" );
GRSPrintfMX( pNode->mTransformation, iBlank + 3 );
GRSPrintfA( "\\n" );
for ( UINT i = 0; i < pNode->mNumChildren; ++i )
{
TraverseNodeTree( pNode->mChildren[i], iBlank + 1 );//累加缩进次数和行数
}
}
这段代码一开始调用了封装的方法GRSGetConsoleCurrentY()得到当前命令行输出位置的y坐标,并保存下来; 接着一大个if判断判定当前递归的节点不是根节点,那么就要利用另一个封装的方法GRSFindConsoleLine()通过父节点或前一个兄弟节点获得它们对应的行号,然后从这个行号到当前输出行的前一行绘制连接用的竖线,中间也调用了几个自定义的辅助方法来暂存当前输出行号和还原当前输出行号。最后再当前行输出本节点的数据,然后递归自己的子节点。这其实是一个典型的基于树型结构的“先序”递归遍历。只要数据结构和算法的基本功好,那么这个方法也就不难理解了。关于本章用到的命令行方法都封装在了GRS_Console_Utility.h和GRS_Console_Utility.cpp文件中,并且一并都传到了Github中,详细的细节大家可以自行阅读源代码,都是Windows Console API的简单封装,阅读理解应该没什么困难。
这里要提示大家的是,这个递归逻辑结构,也是下一讲3D骨骼动画中遍历骨骼树解算动画算法的基本骨架,所以请各位务必要彻底搞明白这个函数的逻辑,以防止下一讲时学习太过吃力。
7、关于引用ATL的说明
在本章代码中,大量使用各种ATL头文件、宏定义、辅助方法、以及各种ATL类,现在它们都有等价的STL替代物,同时ATL也是比较古老的一个类库了,那么为什么我还要使用这个类库(严格来说是一套模板库)呢?主要是因为以下几点原因:
1、从本质上说D3D12接口仍然是基于古老的Windows COM框架体系的,用ATL有一种天然的亲缘性,比如对HRESULT数据类型的处理上,ATL库就有丰富的方法和类支撑;
2、ATL的使用上比较轻量级,基本可以做到用什么就包含(#include)什么,而不用关联别的头文件或库,也不需要预编译之类的麻烦事情;
3、ATL比较简单易理解,没有过渡封装的架构理念,比之STL学习成本要低,功能上也类似,不笨重;
4、最最重要的原因就是VS2019或者说VS系列IDE环境在调试时,ATL模板类中的数据都可以轻松监控察看,具有调试时极其直观的天然优势,这是本人一直比较喜欢用ATL的原因;当然现在的VS2019在调试STL也做了极大改进,也可以方法轻松的察看模板类里的数据了,但主要一直用这个东西用习惯了,就没在换了;
5、ATL模板库的风格比较简单,容易扩展,对于一些复杂的数据结构完全可以照猫画虎自行封装,网上也有一些基于ATL的扩展,比如WTL等,但我还是比较喜欢自行扩展,这样既可以锻炼数据结构的基本功,而且也可以聚焦于自己的扩展,而STL要做类似的扩展难度曲线太陡峭,不是本人喜欢的风格;
6、关于跨平台,目前来说ATL中用到的一些容器模板的封装跨平台编译使用应该是没有啥问题的,而其它部分本来就是为Windows平台设计的,也没有什么跨平台的价值,当然这些示例教程中也没怎么运用过多的平台相关的ATL模板类。所以这也不是大问题。
总之,这个是个纯粹个人习惯的问题,使用ATL的根本宗旨就是为了保持示例的简单性,毕竟本系列教程的核心任务是带领大家一起学习D3D12编程的,并不是教大家如何运用数据结构的,所以不用在这个问题上过多纠结。如果你对STL了解比较深刻,那么就大胆去用STL,只要完全掌握了D3D12接口,它们都只是工具而已,而工具是从属于人的!







![[转]我国CAD软件产业亟待研究现状采取对策-卡核](https://www.caxkernel.com/wp-content/uploads/2024/07/frc-f080b20a9340c1a89c731029cb163f6a-212x300.png)







暂无评论内容