
本系列文章主要翻译和参考自《Real-Time 3D Rendering with DirectX and HLSL》一书(感谢原书作者),同时会加上一点个人理解和拓展,文章中如有错误,欢迎指正。
这里是书中的代码和资源。
本文索引:
文章目录
文章目录
#DirectX11 渲染管线
一般计算机中共有两个处理器是你可能会对其进行编程的,一个是central processing unit(CPU),一个是GPU。这两个组件有着截然不同的硬件结构和指令集。在图形编程领域,你编写的软件可能两方面都要涉及,对于CPU,你可能会使用到例如C++这样的编程语言,而对于GPU则需要使用诸如HLSL这样的语言。大部分关于图形编程的文章要么集中于CPU方面要么是GPU方面,这些内容其实都是有紧密联系的。在本书中,你将可以同时了解到两方面的内容。
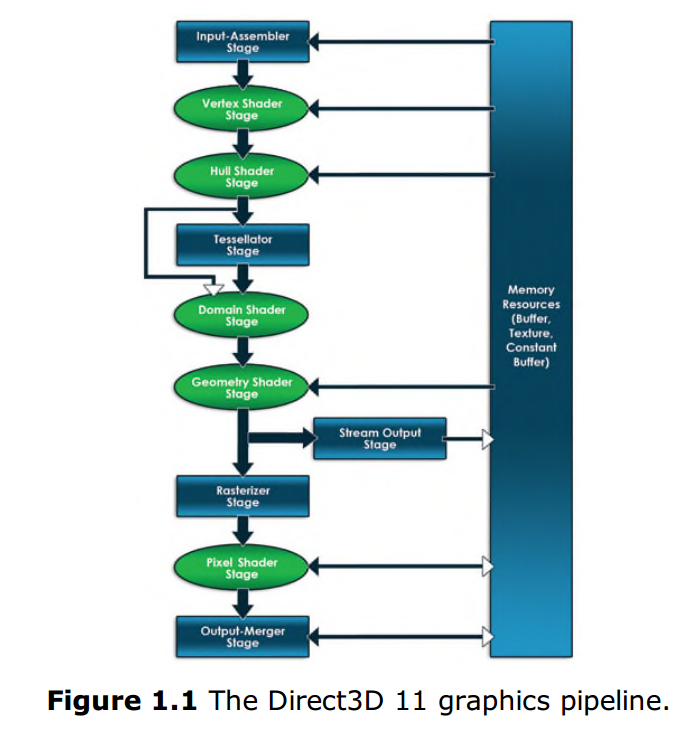
DirectX当中的DirectX 3D API是本书着重关注的部分。Direct3D是用来绘制3D图形的系统接口,他还定义了怎样将实时图形渲染到屏幕的一系列步骤。这些步骤就被称之为DirectX3D图形渲染管线(详见图1.1)。在这张图中,单向箭头标识了数据是怎样从一个阶段传输到下一个,双向箭头则标识了资源和哪些渲染阶段间可以进行数据读写。那些可以用HLSL编程的模块已经用椭圆形标识出来。接下来的内容将会详细介绍渲染管线中的各个模块。

##一、 输入装配阶段:The Input-Assembler Stage(IA)
输入装配阶段是渲染管线的入口,也是第一个阶段,在这个阶段里你需要提供待渲染对象的顶点和索引数据。输入装配阶段将这些数据“装配”成基本类型数据(例如:点列表,线条带,三角列表)并根据需要将数据输出给顶点着色渲染阶段。
###(1) Vertex Buffers顶点缓存
一个顶点至少包含了在3D空间中的一个位置。之所以说至少是因为顶点还可以包含颜色信息,法线信息(用于计算光照),纹理坐标信息等等。所有这些数据都可以在输入装配阶段进行顶点缓存。Direct3D中定义的这些顶点信息完全可以由程序员进行操作。你可以定义顶点所要包含的信息并通过input-layout对象定义顶点缓存数据如何流入IA阶段。之后的文章(原书Part III,Rendering with DirectX)中将会介绍如何定义顶点缓存以及input layout对象,现在只是大概的介绍一下这些术语。
两个顶点代表线段的两个端点,三个顶点可以代表一个三角形(如图1.2)。

###(2) Index Buffers索引缓存
索引缓存是第二种在输入装配阶段推荐的输入类型。索引缓存的定义关联了顶点缓存中的某些顶点,可以用来减少需要多次使用到的顶点的重复。想象以下场景:你需要渲染一个矩形(或宽泛的说,四边形)。这个四边形至少需要定义四个顶点。但是Direct3D并不支持将四边形作为基础类型(因为根本没有必要专门定义一个四边形,所有的四边形都可以拆分成三角形)。为了渲染这个四边形,你需要将其拆分成两个由三个顶点构成的三角形(如图1.3)。所以,现在你需要总共六个顶点信息,而不是四个,其中必然有两个顶点信息是重复的。但如果定义了索引缓存,你就可以通过定义四个顶点信息和六个与顶点缓存相关的索引信息来完成渲染。

现在,你可能会思考一个问题,“我怎么通过增加索引缓存来减少我所使用的整体数据大小呢?”那么我们需要再考虑两种情况,通过结合上面提到的四边形进行具体数据分析:
- 第一种情况
你的顶点数据只包含3D位置信息(x,y,z),每个轴向需要一个32-bit来保存这个浮点数(每个轴向为4byte),那么每个顶点需要12byte。所以在不包含索引缓存的情况下这个四边形只需要72字节保存(6 vertices * 12 bytes/vertex)。如果加上索引缓存,你的顶点缓存需要的空间是48byte(4 vertices * 12 bytes/vertex)。以16bit的int类型数据来保存索引,则你需要额外12bytes(6 indices * 2 bytes/index = 12 byte)。这时,总共需要60byte来存储这个四边形。这么看的话好像也没节省很多空间。
-
第二种情况
当你的模型中不仅包含位置信息,还可能包含16byte的颜色信息,12byte的法线信息以及8byte的纹理坐标信息。那么每个顶点将需要多花费36byte的空间。或许当模型不是太大的时候并不会有很多影响,但如果模型具有成千上万的点时你会发现多出来的空间占用是相当可观的。还有,你不仅需要考虑空间占用的大小,还有当CPU和GPU之间进行数据传输时,是需要通过图形总线(例如PCI Express)来传输的,这种总线的传输速度通常非常慢(相比于CPU向RAM传输,以及GPU向VRAM传输),所以如何减少数据对你来说将会是至关重要的。
###(3) Primitive Types基本类型
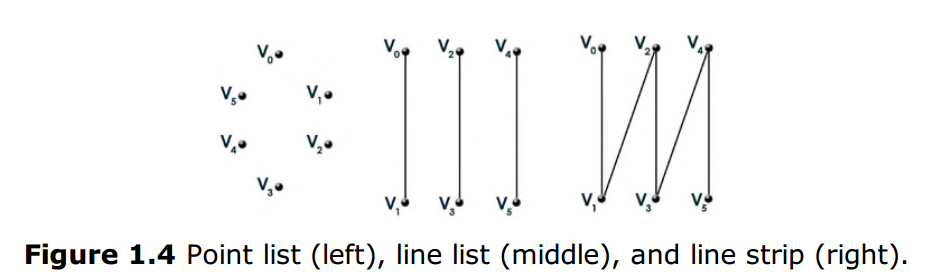
当你向IA阶段提供顶点缓存数据时,你也必须定义这些顶点的拓扑结构,这决定了渲染管线将如何解释执行这些顶点。DirectX3D提供了以下几种基本类型(如图1.4和1.5): -
Point list 点列表:一系列单独渲染毫无关联的点
-
Line list 线列表:一系列成对关联的点,这些一对一对的点之间是没有关联的
-
Line strip 线条带:一系列成对关联的点,但每对点的末点会和下一对点的起点有关联
-
Triangle list 三角列表:是我们最常见的拓扑结构,在三角列表中每三个顶点组成一个独立的三角形。三角形之间公用的点将会重复出现(除非定义了索引缓存)。
-
Triangle strip 三角条带:每三个顶点构成一个三角形,公用的顶点将不会重复,所以顶点间会密切的连在一起。



###(4) Primitive with Adjacency邻接基元
从DirectX10开始,Direct3D已经加入了包含邻接数据的基本数据。对于邻接基元来说,你不只要定义基本数据,还需要定义围绕在这个基元周围的数据。(如图1.6)这是用来做几何着色器的,这里每个特定的集合着色程序需要访问邻接三角形。临界三角形需要和原始三角形一起被提交给顶点/索引缓冲区,并且用D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST_ADJ这个拓扑结构。注意到邻接三角形只是被用来作为几何着色器的输入,并不会被画出来。如果没有几何着色器,邻接三角形也还是不会被画出来。

###(5) Control Point Patch Lists控制点片
控制点片作为一个拓扑结构提供给细分曲面阶段使用。相关内容将会在原书的第二十一章"Chapter 21, Geometry and Tessellation Shaders"中介绍。
| 参考文章:关于输入装配阶段的详细内容和具体实现请参考[这篇文章](http://www.aiseminar.com/bbs/home.php?mod=space&uid=3&do=blog&id=2622) |
##二、 顶点着色阶段:The Vertex Shader Stage(VS)
顶点着色阶段主要处理从IA阶段输出的原始数据。这个阶段会对每个顶点做单独的处理。是渲染管线中第一个可编程的阶段。实际上,不论什么时候都需要程序员或软件提供一个顶点着色器给这个阶段使用。那么到底什么是着色器?
着色器是一段简短的程序或者方法,你所写的东西会直接在GPU上运行。顶点着色器会通过渲染管线在每个顶点上执行一次,在执行完一系列指令之后再输出到下一个阶段。如前一篇文章所提到的,输入到顶点着色器的数据至少应该包含顶点位置。一般情况下,顶点着色器将顶点数据做某种形式的转换之后再输出成一系列新的数据。下图是一个最简单的顶点着色器:

##三、 细分曲面阶段:Tessellation Stage
这是DirectX11新加入的特性,硬件细分曲面是在GPU上直接对模型增加细节的过程。一般来说,更多的几何细节(如更多的顶点)将会带来更好的渲染效果。如图1.7所示:

上图展现了同一个模型使用低中高细节展示的效果。LOD模型一般是由艺术家或模型师创建出来并根据距离摄像机的大小来选择要使用哪种细节的模型。
| 注意:如果距离摄像机视野较远,即使是高细节的顶点数的模型也会有很多细节遗失。所以我们需要根据距离摄像机的远近来选择具体使用的模型——离摄像机距离越远,细节越低。 模型细节越少,顶点着色器需要处理的数据就越少,渲染效率越高。 |
传统的LOD系统中,你需要将你的模型修改成不同的LOD细节模型。硬件细分曲面技术使你能够将一个模型动态的细分并且不耗费额外的多边形数据传输到IA阶段。这样就可以实现动态LOD系统并且使得数据传输总线的占用率更低。DirectX11中,以下三个阶段都依赖细分曲面技术:
- The hull shader stage(HS)外壳着色器阶段
- The tessellator stage
- The domain shader stage(DS)域着色器阶段
HS和DS阶段都是可编程的,但细分阶段则不可以。详细内容将会在原书的21章节介绍。更多内容了解可参见百科。
##四、 几何着色阶段:The Geometry Shader Stage(GS)
不像顶点着色器是基于每个单独的顶点进行运算,几何着色器是基于完整的基本数据来运算(如点,线,三角面)。并且,几何着色器有能力去增加或减少渲染管线中的几何数据。这个特性可以用来实现一些很有意思的效果。例如:你可以实现一个粒子系统,这个粒子系统中的每一个顶点代表一个粒子。在几何着色器中,你可以围绕中心点创建很多四边形,并为这些四边形映射纹理。一个很有名的例子是point sprites(点精灵)。
与几何着色阶段相关的是stream-output stage(SO)输出流阶段。这个阶段将会把几何着色阶段输出的数据存储在内存中。在多通道渲染中,这里的数据可以读回渲染管线在后面的通道中渲染,也可以提供给CPU读取。如细分曲面阶段一样,这个阶段同样也是可选的。原书的第五部分"Part IV, Intermediate-Level Renderring Topics"中会详细介绍这一部分。
##五、 光栅化阶段:The Rasterizer Stage(RS)
在之前所提到的渲染管线中,我们已经讨论了顶点数据以及如何将顶点数据转化成基本数据。光栅化阶段会将这些基本数据转化成光栅化图像,或者说位图。光栅化图像使用二维数组保存并且显示在电脑屏幕上。
光栅化阶段决定了哪些像素将会被渲染到屏幕上并且传递到像素着色器中。在光栅化阶段,会将基本数据以每个顶点进行插值计算。例如,一个三角面片有三个顶点,每个至少包含了一些位置信息,或者还包含了例如颜色,发现,纹理坐标之类的信息。光栅阶段将顶点之间的那些像素插入中间值。图1.8展示了顶点颜色插值的概念。该图中,三个点分别被赋予红色,绿色和蓝色。注意像素在三角形的三个顶点间颜色是如何渐变的。

##六、 像素着色阶段:The Pixel Shader Stage(PS)
从技术角度来说,你需要为像素着色阶段提供像素着色器。这个阶段将会为每个从光栅化阶段输出的像素执行你的着色器。这使得程序员能够控制每个即将输出到屏幕的像素点。像素着色器使用已插值的顶点数据,全局变量和纹理数据进行处理后输出。如下展示了一段将每个像素输出成红色的着色器。

##七、 输出混合阶段:The Output-Merger Stage(OM)
输出混合阶段会产生最终需要被渲染的像素。这个阶段是不可编程的(意味着你不能为这个阶段编写shader),但是你可以定义这个阶段在用户自定义管线状态时的表现 。OM阶段会通过合并状态,像素着色器阶段的输出以及渲染目标仍然存在的内容来产生最终项目。这意味着,通过一些有趣的特效,可以产生透明物体的额颜色混合。相关内容在原书的第八章"Chapter 8, Gleaming the Cube"章节会详细介绍。
OM阶段同时也会通过深度测试(depth testing)和模板测试(stencil testing)来决定哪个像素可以被最终渲染。
深度测试使用之前已经被写入渲染目标(Render Target)的数据来决定哪个像素需要被绘制。如图1.9所示,几个物体排成一排,一个比一个更接近摄像机,他们都存在于同一个屏幕空间中。前面的物体可能完整或者一部分遮挡了后面的物体。深度测试利用物体和相机中每个像素的距离来决定渲染目标。通常,如果已经在渲染目标中的像素比正在被考虑是否要渲染的像素离摄像机的距离更近,则新的这个像素点将被抛弃。
模板测试使用蒙版来决定每个像素是否要被更新。这个概念类似于呈现一个具有物理表面特性的纸箱或塑料制品。详细内容会在原书的第三部分"Part III, Rendering with DirectX."中介绍。
| 注意:光栅化阶段同样可以决定哪些像素将会被渲染到屏幕中,光栅化阶段中的这个过程称为裁剪(clip)。任何被光栅化阶段认定为不在屏幕中的像素都会被直接裁剪,不会再传送到渲染管线后面的流程中进行处理。 |






![[转]我国CAD软件产业亟待研究现状采取对策-卡核](https://www.caxkernel.com/wp-content/uploads/2024/07/frc-f080b20a9340c1a89c731029cb163f6a-212x300.png)




暂无评论内容