
本期为GAMES104《现代游戏引擎:从入门到实践》视频公开课文字实录第11期。本课程由GAMES(图形学与混合现实研讨会)发起,游戏引擎技术专家王希携手游戏引擎一线开发者共同研发。
课程共计22个课时,将介绍现代游戏引擎所涉及的系统架构,技术点,引擎系统相关的知识。为配合学习实践,课程组在 GitHub 上开源了小引擎Piccolo,上线1个月即获得了2900+star, 累计下载量已超过20000+。
以下内容为公开课视频转文字版本,为阅读通顺,有删减
01「渲染系统对象」
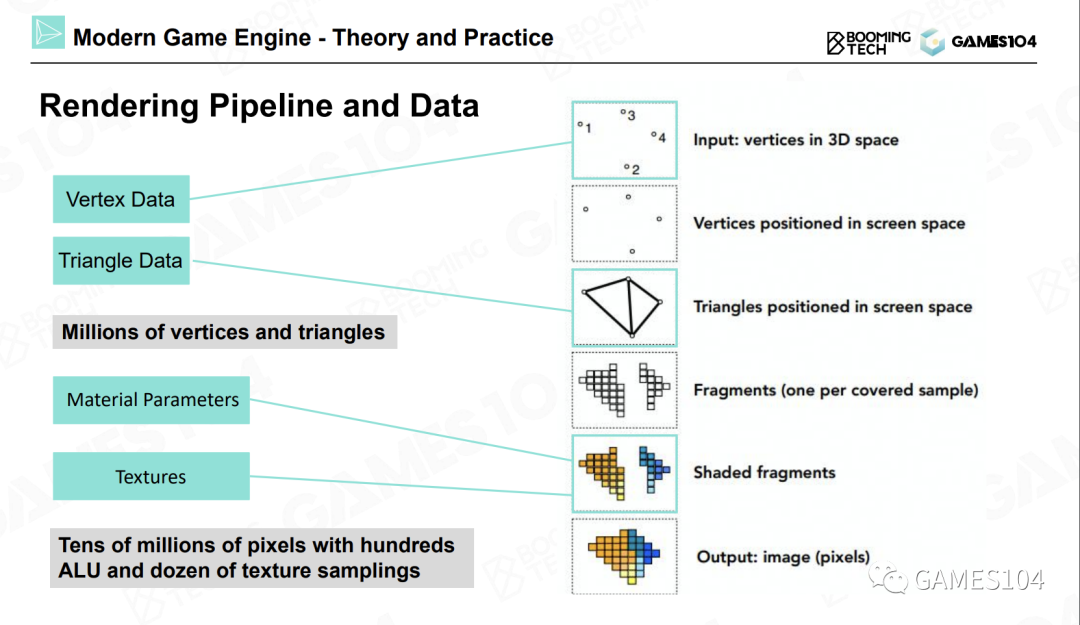
在计算机中,游戏世界是通过顶点及其相关信息来表示的。在空间中存在着很多顶点,顶点连成一个个三角形,三角形又形成了一个个面,这些面经过一个投影矩阵投影到屏幕上。
然后通过一个称为光栅化(rasterization)的过程,将三角形光栅化成一个个像素点。然后在每个小像素点上,我们去寻找这个像素点对应的材质和纹理,将这个像素点渲染成各种各样的颜色。
同时考虑光照、以及物体本身的花纹等信息,并渲染出最终的效果。简单来说,在这个过程中,会涉及到上百万数量级的顶点和三角形、数千万级的像素、以及10亿级的ALU和纹理运算。这就是渲染所涉及的最基础的操作。因此,绘制的最核心工作就是计算(Computation)。

实际上,绘制系统相对于游戏引擎来说,就是做这种躲在像素之后的工作。某年的SIGGRAPH上,在一个介绍游戏引擎绘制的Section中,曾经提到过一句话,叫做“the man and women behind pixel”,就是躲在像素之后的男人和女人们。因为大家看到的每一帧壮丽的游戏画面,都是现代计算机一个一个像素计算并拼接起来的。
在这个过程中,首先需要进行的计算就是投影和光栅化。我们设定一个相机位置,然后对物体进行投影(无论是正交投影还是透视投影),就可以得到屏幕空间中的三角形。在这之后,再将屏幕空间中的三角形光栅化成一个个的像素。

在投影和光栅化之后,需要进行的计算过程就是着色,也叫做绘制。下图是一段示例的着色器代码:

大家会发现,上图示例中的着色代码所涉及的运算也就只有几种。首先,着色器代码需要通过常量获取很多数值,比如屏幕的长宽(以像素为单位)。这些常数在每个像素的着色代码中都要进行访问。然后,着色器代码会进行大量的加减乘除运算。
比如我们需要计算一个Phong模型,我们需要知道法线位置、光源位置、人眼位置。通过这些信息,就可以计算出光线衰减的百分比。如果图中的小球上有很多花纹,我们就需要将花纹的纹理存储到一张2D贴图上,着色器代码再将自己所处理的像素点所对应的纹理贴图上的坐标的相应位置上的颜色值取出。通过这几种运算,即常数访问、变量访问,再加上纹理访问,我们就可以得到想要的结果。
需要注意的是,在绘制过程中,有一个大家经常会忽略的过程,它的性能消耗非常大,也十分复杂,这就是纹理采样(Texturing)。

举个例子,我们需要绘制一面砖墙。当砖墙离相机很近的时候,你会看到一个一个的像素。如果这个砖墙离相机非常远,这时候你在屏幕上看到的每一个砖墙的像素,在砖墙的纹理上是隔了很多像素的。如果我们不对纹理进行滤波(这里的情况是低频滤波)操作,当砖墙相对于相机由近及远移动时,画面就会发生抖动。这就是走样。大家在玩游戏时,会发现有一个图形设置选项,叫做反走样。
在实践中,对于每一张纹理贴图,我们会存很多层,当着色器为屏幕上的一个像素点进行纹理采样时,采样位置可能并不一定正好位于该像素点上,因此需要取四个点,并对这四个点进行插值。同时还需要在两层纹理上按照比例采样。
同学们可以思考一下,如果进行一次纹理采样,需要访问多少数据,需要进行多少次插值?
答案是:进行一次纹理采样,需要采样八个像素点的数据,并且进行七次插值运算。因此,纹理采样是绘制过程中的一个很重要的运算。
02「了解GPU」
在实践中,游戏绘制系统是无法运行在我们假设的理想设备上的。因为这并不是一个理论证明题,即我们在理论上证明它是正确的就可以了。恰恰相反,游戏绘制系统的实现是一个实践性问题,它需要运行在各种性能的现代硬件上。
下面我们介绍GPU(Graphic Processing Unit),即日常所说的显卡。

显卡是一个非常伟大的发明创造。我们在第一节课中介绍过,现代游戏引擎之所以能够有突飞猛进的变化,就是因为随着独立显卡的出现,我们可以将这些复杂的运算用一台更高效的机器进行处理,这样可以释放出大量的CPU时间。
同时,我们可以将画面越做越精细。因此,如果同学们想成为一个游戏引擎图形程序员,那么显卡就是你最好的伙伴。此外,现代游戏引擎中的绘制系统的很多基础设计,也是人们基于对现代显卡架构的理解而构建的。
下面介绍的内容会帮助同学们建立对显卡基础架构的理解。让大家知道在架构一个渲染系统时,需要关注哪些方面。
首先,大家需要了解两个概念:
SIMD(Single Instruction Multiple Data)
SIMT(Single Instruction Multiple Threads)

大家可能对SIMD略有耳闻,因为SIMD已经被广泛用在现代CPU中,即单指令多数据的数学运算。对于一个四维向量来说,每进行一次加法操作,它的XYZW坐标会同时进行运算。所以一条指令就能够完成四个加法或者四个减法运算。同学们在阅读C++代码的过程中,如果看到SSE扩展宏,下面的代码实际上就是在调用SIMD指令。渲染过程中有很多运算都适用于SIMD运算,比如矩阵运算、坐标变换运算等。现代显卡中还有另外一个更加有趣的概念,叫做SIMT。即将一个计算核心做得很小,这样可以同时提供多个计算核心,并且可以同时在多个核心上执行同一条指令。
如果我们有100个计算核心,向这100个核心发送一条指令,就可以同时进行100次四维向量的加减。相当于将一条指令的计算效能放大了400倍。现代显卡如同一个蜂巢,其中内置了很多小型计算核心。NVIDIA的显卡中就内置了很多称为CUDA的计算核心。这就是现代显卡算力强悍的原因。
这里给大家介绍一个名词:FLOPS(floating-point operations per second)。FLOPS代表着显卡的浮点运算能力,即每秒浮点运算次数。现代显卡一般能够达到十个以上的TFLOPS,比如Xbox或者PS5。
然而,现代CPU的算力很难达到一个TFLOPS,显卡和CPU的算力差距已经超过了一个数量级。为什么显卡的算力能够遥遥领先于CPU呢?本质上是因为显卡中具有大量可以同时进行并行计算的小型计算核心,每个核心的功能简单,只可以进行简单的计算。而CPU的核心数量很少,但单个核心的计算能力很强。
因此显卡的并行计算能力十分强大。因此,我们在设计绘制算法的时候,要尽可能地利用SIMT结构的优势,尽可能使用相同的代码进行并行计算。这样一来,每个计算核心都可以分别访问自己的数据,这样可以充分发挥显卡架构的优势。这是图形程序员需要掌握的一个最重要的概念。

上图是某款现代GPU的架构图,虽然复杂,如果大家仔细观察,就会发现,图中的结构是重复的。图中展示的是大约十年前由NVIDIA发布的费米架构。在费米架构中,内置了很多核心,并且被分成了很多组。
在每个图形处理集群中,有很多流式多处理器,而在每个流式多处理器中,都装有很多的小型核心。计算机术语中称为ALU(Arithmetic Logic Units,算术逻辑单元)。在NVIDIA的显卡中称为CUDA,CUDA核心负责进行数学运算。如果向流式多处理器发送一条指令,这些CUDA核心就可以同时执行同一条指令。
同时,会有专门的硬件处理各种耗时的纹理采样工作,以及一些比较复杂的数学运算。比如正弦、余弦、指数、对数等超越函数运算。因为超越函数的运算速度比较慢,所以显卡中有一些专门的SFU(Special Function Unit,特殊功能单元)负责处理这些运算。最新的Ampere架构中,还有一个Tensor Core,这就是用于人工智能处理核心。
同时还有一个RT Core,这是用来加速光线追踪BVH算法的硬件逻辑电路。这就是现代GPU的架构。也就是说,在GPU上的运算都会被分配到每个流式多处理器上进行处理。而流式多处理器中的几十个核心不仅可以进行并行处理,相互之间还可以交换数据,从而进行协作。因此费米架构中的流式多处理器相对于之前的架构增加了共享内存(Shared Memory)。如果同学们有过并行化编程的经验,就会知道,如果CPU之间还可以交换数据,那么就可以实现一些非常酷炫的运算。以上大致说明了SIMT的概念。

下面介绍一下数据在计算机中流动的成本。从计算机诞生时,我们一直使用的都是冯洛伊曼架构,即将计算和数据分开。这样的架构会让硬件设计变得非常简单。现在也有一些很前沿的研究在研究如何突破这个架构。冯洛伊曼架构的最大问题是,每一次计算,都需要去获取数据。后来人们发现,获取数据的操作速度非常慢,而且数据在不同的计算单元中搬来搬去也是非常之慢。以我们本节课程开始时提到的南桥和北桥芯片来说,北桥芯片连接着CPU和显卡,CPU用到的数据放在主内存中。
如果想将CPU准备好的数据上传到显卡的显存中的话,这个上传速度是非常慢的。还有一个问题,如果CPU已经准备好数据交给显卡去计算,但需要等显卡计算完毕之后,再将结果从显卡回读到CPU,CPU再基于显卡的计算结果进行一些判断,然后再告诉GPU如何进行绘制。这称之为数据的“Back Force”。
这一过程存在一个非常严重的问题,在现在引擎架构中,绘制和逻辑通常是不同步的。如果有一步绘制运算需要等待数据的“Back Force”,则可能会导致半帧到一帧的延迟(Latency)。游戏中的逻辑和画面不同步的问题,有时就是因为这个原因。因此,在游戏引擎的绘制系统架构中有一个原则,就是尽可能将数据单向传输。即CPU将数据单向发送到显卡,并且尽可能不要从显卡中回读数据。这也是现代计算机结构对渲染系统设计的一个限制。
下面介绍一下缓存(Cache)的概念。

缓存对于现代计算的性能影响是非常大的,可能远远超过大家的想象。举例来说,在现代CPU上,如果进行一次数学运算,可能一个时钟周期就做完了。但如果这个时候,比如CPU正在进行A+B的运算,而A的数值CPU需要从内存中获取。这时,如果CPU发现A不在自己的缓存中,而需要去内存中读取A的值,实际上它需要等待100多个时钟周期才能从内存中得到A的值。在等待的这段时间里,CPU理论上可以进行几十次到上百次数学运算。这也是上节课中提到过的数据一定要放在一起的原因,其实就是为了缓存去做这样的准备。因为数据连贯性对于缓存来说非常重要。如果有些数据过大,那么也会导致缓存很难被利用好。
在每次计算时,如果所需要的数据刚好都位于缓存中,则叫做缓存命中。如果所需要的数据不在缓存中,则叫做缓存未命中。这时,CPU就需要等待很多时钟周期,才能获取到数据。
所以大家在从事计算机图形学和游戏引擎的相关开发时,如果纹理采样等计算没有设计好,使得计算过程中经常发生缓存未命中事件,计算效率就会直线下降。
如果大家以后有机会进入到图形程序员相关的岗位,将会学会很多行话。比如“ALU Bounds”,这个说法是指程序的数学计算太多,而其他的操作(比如纹理采样等)都能够及时完成,但需要等待数学运算的结果。
还有填充率限制(Fill Rate Bounds),这个说法是指所有的数学运算都完成了,但是写入缓存的速度太慢,结果导致数据传输发生了堵塞。大家会发现,现代计算机就是一个流水线,只要有一个环节没有平衡好,就会发生卡顿,而其他环节优化得再快,整个流水线也会被卡住。所以“Bounds”这个词是一个最常用的行话。以后大家进入到游戏开发行业,会熟悉更多的行话和黑话。
现在,大家应该可以理解,对于现代的游戏,特别是非常复杂的顶级游戏来说,为什么开发人员在进行渲染系统的设计时,需要特别关注对GPU的使用和利用。
硬件的架构也一直在不断演进。大约十年前,从DirectX 11时代开始,GPU就可以完成更高级的曲面细分,以及实现更加灵活的Shader,包括更通用的计算Shader等功能。实时今日,GPU也可以支持更加容易处理的Mesh Shader。而主机的架构又有所不同,因为主机使用的是一种叫做UMA的共享内存架构。因此,主机上使用的游戏引擎的架构又会不同于PC上所使用的架构。还有一个平台就是手机游戏平台。
手机游戏运行在移动端,移动端最关注的指标是功耗,因为移动端芯片的处理能力有限,而数据访问对于移动端来说是一个相当昂贵的操作,因此人们开发出了“Tile-Based Rendering”(分块渲染)技术。大家所看到的手机上呈现的游戏画面(比如1080P或者4K分辨率的画面),其实是分块渲染出来的。
换言之,所有的引擎架构都是和硬件架构息息相关的。所以同学们在学习渲染之前,需要先了解显卡的工作原理。一旦理解了显卡的工作原理,就会对各种渲染引擎的算法产生更加深入的理解。这部分同学们听不懂没有关系,建立一个基础概念即可。
如果大家后续不会从事引擎开发,但是会从事游戏开发的相关工作,比如游戏美术等。我个人认为,掌握这些概念还是有用的。
因为当你去设计你的游戏玩法的时候,你会知道,硬件上会有哪些限制,所以我们不能将场景做得无限复杂,而只能更专注于游戏的玩法体验。
本文编辑:Piccolo 社区编委会 彭渊

如对本节课有任何问题,欢迎加入我们的社群或给我们发送邮件:
piccolo-gameengine@boomingtech.com
关于我们
Piccolo游戏引擎社区
Piccolo社区是中国开源游戏引擎社区,由游戏引擎行业大佬、共创官、学习者共同建立。你可以在我们的社区里交流技术、互助问答、参加活动,你也可以参与Piccolo 的共建,如撰写贡献代码、撰写技术文章、参与技术挑战等。
Piccolo游戏引擎
由中国游戏引擎社区Piccolo开源的一款Mini游戏引擎。采用世界-关卡-游戏对象-组件的简洁架构,便于理解游戏引擎架构思想,它不仅能有效的帮助开发者学习游戏引擎架构知识,也能帮助一线开发者实验引擎算法与第三方库、辅助个人项目快速启动。截止目前,Github点赞已突破3600+,累计下载量已超过20000+
Piccolo GitHub地址:https://github.com/BoomingTech/Piccolo/discussions
关注公众号GAMES104,回复【入群】,加入Piccolo社群






![[转]我国CAD软件产业亟待研究现状采取对策-卡核](https://www.caxkernel.com/wp-content/uploads/2024/07/frc-f080b20a9340c1a89c731029cb163f6a-212x300.png)